
캐시의 개념과 종류 / 쓰기 정책과 교체 정책 본문
Cache
매번 느린 메인 메모리에서 instruction을 가져오는 것이 아닌 프로세서와 메인 메모리 사이에 위치하여 자주 사용하는 명령어를 더 빠르게 가져올 수 있도록 하는 기술이다. instruction을 fetch할 때, 특히 같은 구간을 반복해서 fetch할 때, memory안 어떤 주소의 데이터(명령어)가 바뀌지 않는다면 메모리에서 바로 명령어를 가져오는 것이 아닌 좀 더 작고 빠른 장치에서 해당 주소에 해당하는 데이터를 기억해 두었다가 꺼내쓸 수 있는 임시 공간을 만들어서 메모리 접근을 줄인다.
고속의 장치는 비싸다. 가격이 비싸거나, 용량이 적거나, 발열이 크다. 다른 조건(가격, 발열)을 동일하게 한다면 고속의 저장 장치는 더 작은 공간을 갖게 된다. 그 말은 즉 모든 메모리의 데이터가 캐시에 들어갈 수 없고, 기준을 나눠 일부 데이터만 캐시에 매핑되어야 한다.
따라서 메모리 접근을 최소화하는 사용하는 목적과 앞선 저장 공간의 한계라는 특성에 따라 캐시를 사용하는 설계에는 어떤 데이터를 보관할 것이고, 어떤 알고리즘으로 데이터를 교체하는 것이 효율적일 것인지, 궁극적으로 메모리 접근을 어떻게 줄일 수 있을지에 대한 고민이 필요하다.
Index 와 Tag
앞선 저장 공간의 크기 차이로, 일반적으로 캐시에 메모리의 모든 데이터를 1:1로 넣는 것은 불가능하다. 캐시 되어야할 데이터를 선별해야하고 해당 데이터를 어느 공간에 위치시킬 것인지를 결정하는 것이다.
index는 엑세스 주소의 한 부분을 기준으로, 캐시의 데이터 다발 중 어느 위치에 데이터가 저장되었는지를 나타내는 값이다. '쓰기'시에는 엑세스 주소의 인덱스에 해당하는 캐시 위치에 데이터를 쓰고, 다음번 '읽기'시 해당 주소의 같은 부분을 읽어 캐시의 어떤 위치에서 데이터를 꺼내야 하는지 확인하는 것이다.
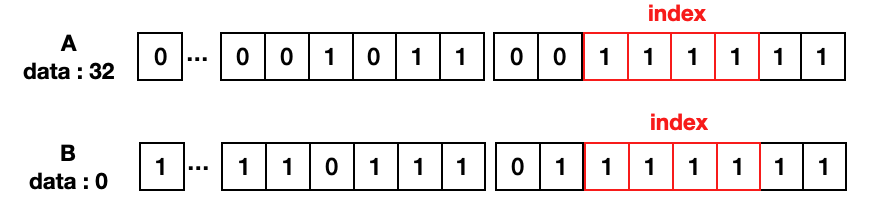
index의 위치를 주소에서 byteoffset 2비트를 제외한 하위 4비트로 예를 들면, A와 B 모두 index 값은 1111으로 캐시내 동일한 위치에 저장되게 된다. A를 저장된다고 하면 캐시의 index : 1111 라인에 A의 값 32가 저장되는 것이다.
이때 같은 인덱스 값을 갖는 다른 주소 B가 읽기 요청을 했다고 가정해보자. B의 데이터를 캐시의 인덱스 1111의 데이터 값으로 해도 될까? A는 그 값이 32이고, B는 0으로 서로 다른 값이니 캐시 라인 1111의 데이터를 믿어선 안된다. 즉 캐시에 B의 데이터는 없는 것이다. 이를 구별하기 위한 값이 또 필요하다. index와 마찬가지로 주소의 일부분을 값으로 인덱스 라인에 해당하는 캐시 값이 엑세스 주소의 데이터가 맞는지 구분한다. 이를 tag값이라고 한다.

Block
앞선 예시에선 캐시에는 여러 데이터 다발(line)이 있고, 다발의 주소 index와 데이터를 1:1를 매핑하였다. Block은 캐시의 line에 여러 데이터를 담는 것을 말한다. 데이터는 지역성으로 가까운 시간에 참조된 데이터가, 가까운 메모리 위치에 저장된 데이터가, 다시 참조될 가능성이 크다. 한번 메모리를 캐시할 때 데이터를 하나씩 가져오는 것이 아니라 곧 다시 사용될 것으로 생각되는 근처 데이터까지 한번에 묶어 가져오는 것이다.
이렇게 Block으로 메모리 fetch, 캐시에 저장하게되면, 앞선 예시의 index로 어떤 line을 확인할 것인지를 위해 index 값을 결정하고, 해당 라인의 어떤 block을 참조할 것인지 다시 확인해야 한다. 이를 위해 block 위치를 표시하기 위한 주소의 offset 비트를 정하고, 주소를 읽었을 때 해당 offset에 위치에 있는 데이터를 확인한다.

이렇게 한번에 여러 데이터를 fetch할 경우, 메모리에서 데이터를 하나씩 엑세하는 것보다 더 많은 시간이 걸리지만, 여러번 데이터를 읽게 되면 메모리 한번에 가져오는 것이 훨씬 유리하다. 메모리에 접근하는 시간이 접근 후 여러 데이터를 참조하는 시간보다 훨씬 더 크기 때문이다.
그렇다고 블록 사이즈가 캐시 성능에 비례하는 것은 아니다. 위 표는 블록 사이즈에 따른 Miss율을 보여준다. Block 사이즈가 커질 수록 한 index line에 포함되는 hit 데이터가 많아지니 일반적으로는 miss율이 낮아진다. 단, 한번 miss가 될 때 memory fetch 시간도 더 커지므로 이 실패 손실과 miss 율 감소를 비교해야한다. 또 블록 사이즈가 매우 크게 되면 블록 내 데이터들의 공간 지역성을 잃게 된다. 극적으로 블록 사이즈를 엄청 크게 키웠다고 가정해보자. 특정 block 사이즈 이상부터는 더 이상 '저장 공간이 가까운' 데이터라는 특성을 잃은 채 모든 데이터를 fetch하려 할 것이다. 이에 따라 miss율이 다시 증가하거나, 감소가 둔화되는 모습을 볼 수 있다.
Valid bit
valid bit는 해당 line의 값이 더미 값인지 아닌지를 구분하기 위해서 사용한다. 예를 들어 tag 초기 값이 모두 0인 경우에, pc의 tag가 0이라면 이 경우 캐시된 값이어서 tag가 동일한 것인지, 초기값이 0이라 값이 동일한 것인지 확인할 방법이 없다. 이 상황을 피하기 위해 valid bit를 두고 초기 값을 false로 하여 캐시에 믿을 만한 tag와 데이터가 들어있는지 표시하는 것이다.
Hit / Miss
캐시 내에 읽고자 하는 데이터가 존재하는 경우를 hit라고 한다. hit 확인 과정은 다음과 같다. 우선 주소에서 index, tag, blockOffset 부분을 확인한다. 캐시의 index에 해당하는 line에 유의미한 데이터가 존재하는지 valid bit로 확인한다. 유의미한 데이터가 존재한다면 해당 line의 데이터가 원하는 주소의 캐시 값이 맞는지 tag를 비교하여 확인한다. tag까지 일치한다면 이를 hit라고 하고, blockOffset에 해당하는 데이터를 꺼내게 되는 것이다.

Set / Direct mapped, Fully associative, N-way set associative
앞선 예시들은 한 인덱스에 한개의 캐시라인(valid bit, tag, data blocks)이 매핑된다. 이 경우 Miss가 되면 다른 선택지 없이 매번 index에 해당하는 캐시 라인을 비워야할 것이다. 만약 한 인덱스에 서로 다른 캐시 라인이 번갈아 사용된다고 생각해보자. 매번 해당 인덱스는 miss 가 발생할 것이고, 매번 memory fetch가 요구되며, 그런 현상은 캐시로써의 의미를 잃는다.
만약 위의 상황에서 해당 인덱스에 두 개의 캐시 라인이 동시에 매핑될 수 있다면 어떨까? 데이터가 요구됐을 때 해당 인덱스에 해당하는 두개 라인을 모두 확인하고 데이터를 엑세스하는 것이다. 같은 상황에서 일단 각각 memory fetch 해두면, 이 두 Line이 요청에 따라 번갈아 엑세스되어 더 이상 miss가 발생하지 않을 것이다. 각각의 캐시 라인이 서로 다른 tag를 갖고 있으면 어떤 라인을 엑세스해야하는지의 데이터 확인에는 문제가 없을 것이다.
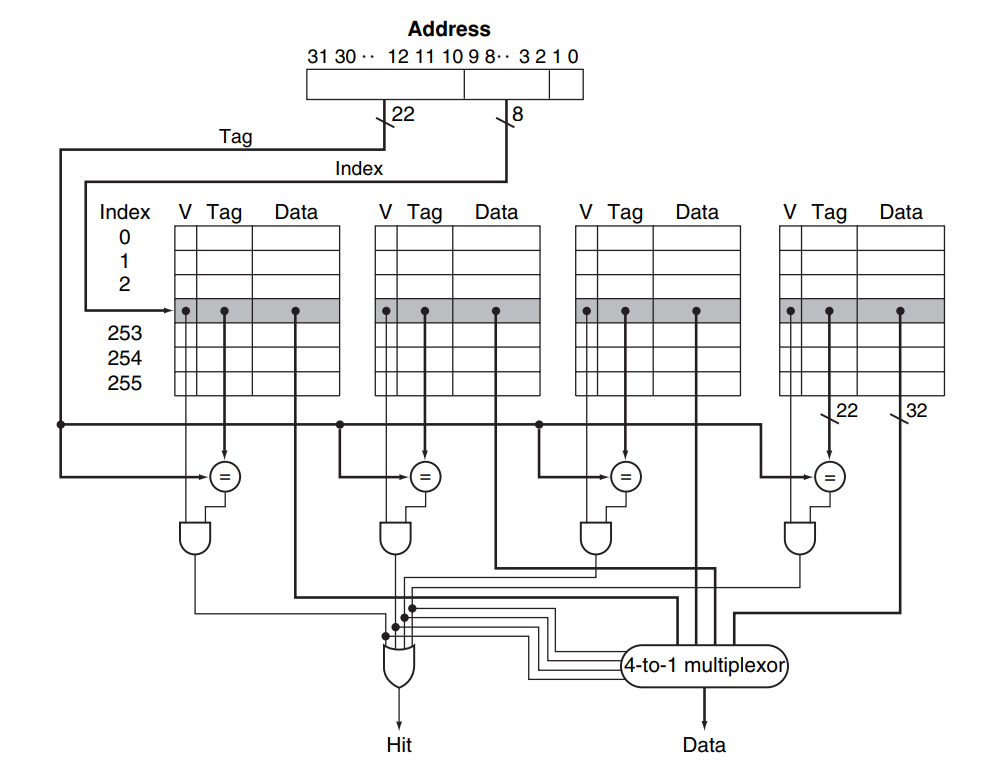
이를 set이라고 한다. 앞선 상황에선 set를 2로 늘린 상황이고, 데이터 read가 발생할 시 이 두 set의 index에 해당하는 cache line을 읽어 tag 값을 비교하여 hit 여부를 확인한다. 위 예시 그림은 32비트 주소 체계에서, byte offset = 2bit, block size = 0bit, set size = 2bit, index = 8 bit인 4-set associative cache의 hit 여부와 data를 얻는 data path이다.
이 set의 수를 기준으로, set 수가 0개여서 index와 cache line이 1:1인 캐시를 직접 사상 캐시(direct mapped), 반대로 cache line을 index 접근이 아닌 모든 line 비교 -> 접근, 모든 cache line이 set로 사용되는 캐시를 완전 연관 캐시 (fully associative)라고 한다. 그리고 이 둘 사이에서 n개의 set를 갖는 방식의 캐시는 n-way set associative cache로 불린다.
결국 direct mapped cache는 1-way cache, fully associative cache는 모든 cacheLine이 set인 m-way cache와 같다. direct mapped cache는 캐시 교체에 선택지를 주지 못한다는 것, fully associative는 모든 선택지를 주는 대신 그만큼 비교를 위한 설계가 추가되어야 한다는 것이고, 이 둘 사이에서 적절한 set의 교체 선택지를 줄 수 있는 방식이 set associative cache인 것이다.
Write through, Write back
Write through(바로 쓰기), Write back (나중 쓰기)는 '쓰기' 명령에 의해 변형된 데이터를 언제 메모리에 반영할지에 대한 전략 차이이다. 이름 그대로 Write through는 변경 사항을 바로 메모리에 반영하고, Write back은 우선 캐시에 먼저 반영하고, 더 미룰 수 없는 상황이 왔을 때 캐시 라인을 메모리에 반영하게 된다.
Write back의 이점은 결국 메모리에 쓰는 메모리 엑세스를 줄인다는 것이다. 매 쓰기 명령어 마다 메모리 엑세스를 하지 않고, 혹 메모리 반영을 위해 쓰기를 하더라도, 각 쓰기는 블록별이 아닌, 블록채로 접근하기 때문에 엑세스 횟수를 크게 줄일 수 있다.
Write back 방식을 사용시 cache line에 변경이 있음을 확인하기 위해 각 line에 dirty 비트를 추가한다. 캐시에 데이터가 반영되는 경우 dirty 비트를 true로 바꿔주고, 해당 cache line이 교체될 때 dirty bit를 확인하여 변경되었으면 이를 메모리에 반영한다. 물론 memory fetch로 새로 cache line이 쓰여졌거나, 캐시가 초기화된 시점에서 dirty bit는 false여야 한다.
Replacement strategy
set가 2개 이상일 때, 캐시 miss가 발생하여 cacheLine을 교체해야하는 경우, 어떤 set을 교체 대상으로 할지에 대한 전략을 말한다. 대표적으로 사용되는 방식으로 다음의 4가지 방식이 존재한다.
1. Random replacement : 후보군에서 랜덤하게 선택한 set를 교체 대상으로 한다.
2. First in, First out : 가장 먼저 등록된 set를 교체 대상으로 한다.
3. Second chance : 한번이라도 사용되는 경우 교체 대상을 피할 second chance를 부여하고, 다음 set를 교체 후보로 한다.
4. Least recently used : 사용에 가장 오래된 set를 교체 대상으로 한다.
'Computer Science > Computer architechture' 카테고리의 다른 글
| 프로세서의 명령어 파이프라이닝 개념과 구현 (2) | 2022.06.02 |
|---|---|
| 싱글사이클 기반 MIPS 프로세서 설계 (0) | 2022.04.24 |
| 명령어 파이프라이닝 / Forwarding과 분기 예측 (0) | 2019.07.01 |
| 프로세서/ single cycle, multi cycle / 싱글 사이클, 멀티 사이클 (0) | 2019.06.28 |
| 컴퓨터 추상화 / 퍼포먼스 (0) | 2019.06.24 |