
ecsimsw
프로세서의 명령어 파이프라이닝 개념과 구현 본문
Pipelining
기존의 파이프라인을 적용하지 않은 멀티사이클 방식은, 한 명령어를 처리하고 그 이후에나 다음 명령어를 처리시켜 ALU를 사용 시에는 메모리가 쉬고, 메모리를 사용 시에는 ALU가 쉬었다. 즉 명령어의 단계 외의 다른 컴포넌트가 IDLE 상태로 처리를 대기하는 식이었다.
파이프라이닝은 여러 명령어를 중첩하여 명령어 처리 단계를 병렬 실행시키는 기술이다. 한 사이클 안에서 여러 명령어를 동시에 처리하여 쉬는 컴포넌트 없이 작업하여 더 효율적인 처리를 가능토록 한다.

위 그림에서의 예시라면 위의 파이프라인을 적용하지 않은 프로세서는 3개의 LW 명령어를 처리하는데 2400ps의 시간을, 아래 파이프파인을 적용한 프로세서는 약 1400의 시간을 사용한다. 이때 3개의 명령어가 아닌, 명령어를 충분히 많다고 가정하면 파이프라이닝 방식에선 매 200ps 마다 명령어가 처리되기 때문에 성능 향상은 명령어 사이의 간격 비율(약 4배)에 근접한다. 파이프라이닝은 개별 명령어의 실행 시간을 줄이지는 못하지만 (한 명령어 처리에 800 사용), 명령어 처리량을 증대시킴으로써 성능을 향상한다.
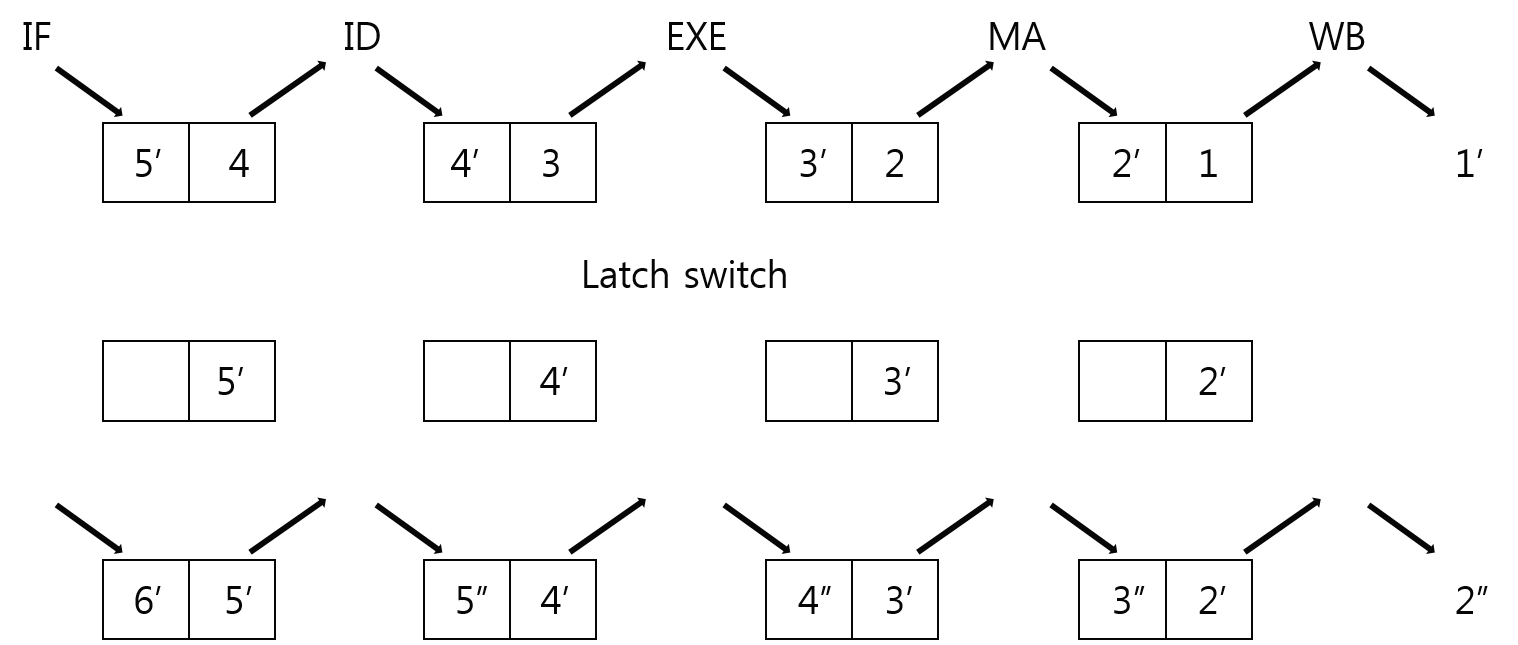
Latch
Latch는 pipelining이 각 단계마다 다른 명령어를 처리하고 그 결과를 다음 사이클의 다음 단계 인풋으로 사용해야 하기 위해 아래 그림과 같이 각 단계 사이에 두고 단계별 인풋과 아웃풋을 저장한다.
한 사이클이 실행되면 latch의 입력부에서 각 단계별 처리 인자를 받아 처리하고, 처리 결과를 다음 단계의 latch의 결과부에 저장한다. 이후 한 사이클이 종료되는 시점에서 latch의 단계별 결과부를 입력부로 옮기는 것으로 다음 사이클에서 입력부를 이전 사이클의 결과부로 하는 것이다.
3 hazards
이런 파이프라이닝을 설계하기 위해선 아래 세가지 문제를 해결해야 한다.
1. 구조적 해저드
한 개 이상의 명령어를 중복된 하드웨어에서 처리하고자 하는 상황을 말한다. 예를 들면 fetch 단계와 memoryAccess단계에서 메모리 자원을 동시에 사용하고자 하는 경우를 말한다. 이런 경우 Bubble을 추가하여 중복 사용되는 하드웨어가 생기지 못하도록 하는 방식이 있을 수 있고, 또는 아예 자원을 추가하여 중복을 피할 수도 방법도 있다. 전통적인 5단계의 프로세서라면 명령어를 담는 메모리 자원과 데이터를 담는 메모리 자원을 분리하는 것으로 fetch 단계와 memoryAccess단계의 메모리 자원을 분리할 수 있게 되는 것이다.
2. 데이터 해저드
명령어가 아직 처리 중인 앞선 명령어에 종속성을 가질 때 발생한다. 예를 들면 일렬의 명령어가 순차적으로 동일한 레지스터 R2를 쓰고, 읽는다고 가정해보자. 각각 execute, decode 단계에 있는 경우 decode 단계의 명령어는 앞선 명령어가 레지스터에 연산의 결과를 저장하지 않은 상태로 decode에서 그 값을 읽어버린다. execute 단계에 있는 '쓰기' 명령어가 writeBack 단계에 가서야 레스터에 값을 저장하기 때문이다.
따라서 이는 앞선 명령어가 writeBack를 처리하기까지 다음 명령어를 대기시키는 방식(Stalling 또는 Freezing), writeBack에 저장될 값이 결정되는 시점의 값을 미리 앞 당겨 사용하는 방식(Forwarding), 또는 아예 컴파일 시점에 컴파일러 수준에서 일정 거리 안에서 사용되는 레지스터의 중복 사용을 피하는 방식으로 해결할 수 있다.
3. 제어 해저드
분기 명령어의 결과를 알기 전까지 fetch 된 명령어의 유효성 여부를 알 수 없는 문제가 발생한다. 명령어가 분기 명령인지 아닌지 또는 분기 명령어가 실행될지, 아닐지 모른다. 분기 명령이 실행되지 않음을 생각하여 우선 다음 pc의 명령어를 fetch 하나, 만일 분기가 맞다면 이를 알게 되는 execute 단계 이전의 fetch, decode는 모두 무의미한 명령어가 수행된 것이다. 반대로 분기 명령어를 실행한다고 생각하였다가 execute 단계에서 분기가 아니라면, 마찬가지로 앞선 단계의 명령어는 무의미해진다.

이런 무의미한 명령어를 어떻게 줄이는가가 제어 해저드를 생각하는 주요 관점이 된다. 앞선 예시의 경우처럼 무의미한 명령어가 발생하면 이를 유효하지 않은 명령어로 처리하는 방법(Branch delay), 이전 분기 결과를 기억하는 등 분기 결과를 예측하는 방법(Branch prediction), 더 나아가 아예 PC와 분기 결과를 기록한 버퍼를 이용하여 decode 단계 이전에 분기 결과를 예측하는 방법 등을 사용한다.
Data dependency / Scoreboarding
명령어 간 데이터 종속성을 어떻게 확인할 수 있을까. 결국 데이터 종속은 쓰기가 완료되기 전에 읽기가 진행되는 경우를 말한다. Scoreboarding은 레지스터에 valid bit를 추가하는 것으로 읽고자 하는 레지스터가 이후에 쓰기가 진행되지는 않는지 확인하는 방식이다.
레지스터에 valid bit를 추가하고, decode 단계에서 '쓰기' 명령어임이 확인된다면, 해당 값을 0으로 하여 유효하지 않음을 표시(book)한다. 이후 writeBack 과정에서 '쓰기'가 완료된다면 그때 해당 값을 1로 하여 다시 사용에 안전함을 표시(release)한다. 이 과정 사이의 '읽기' 명령어는 decode 단계에서 레지스터의 valid bit를 확인하여 읽기에 안전한지, 즉 데이터 종속성이 있는지를 확인하는 것이다.
문제는 이렇게만 하면 다른 쓰기 명령어가 진행 중인 경우에도 '쓰기'를 완료한 명령어가 valid bit를 1로 release 하는 문제가 발생할 수 있다. 더 구체적으로 'WWR'가 순차적으로 실행된다고 생각해보자. 먼저 쓰기가 끝나는 명령어는 다음에 순차적으로 쓰기가 발생하는지 알 수 없고, writeBack이 끝나는 동시에 해당 Reg를 release 한다. 아직 쓰기가 끝나지 않은 명령어가 이전 단계에서 처리되고 있음에도 decode 단계의 읽기 명령어는 해당 Reg의 valid만을 보고 읽기가 가능하다고 오해하게 된다.
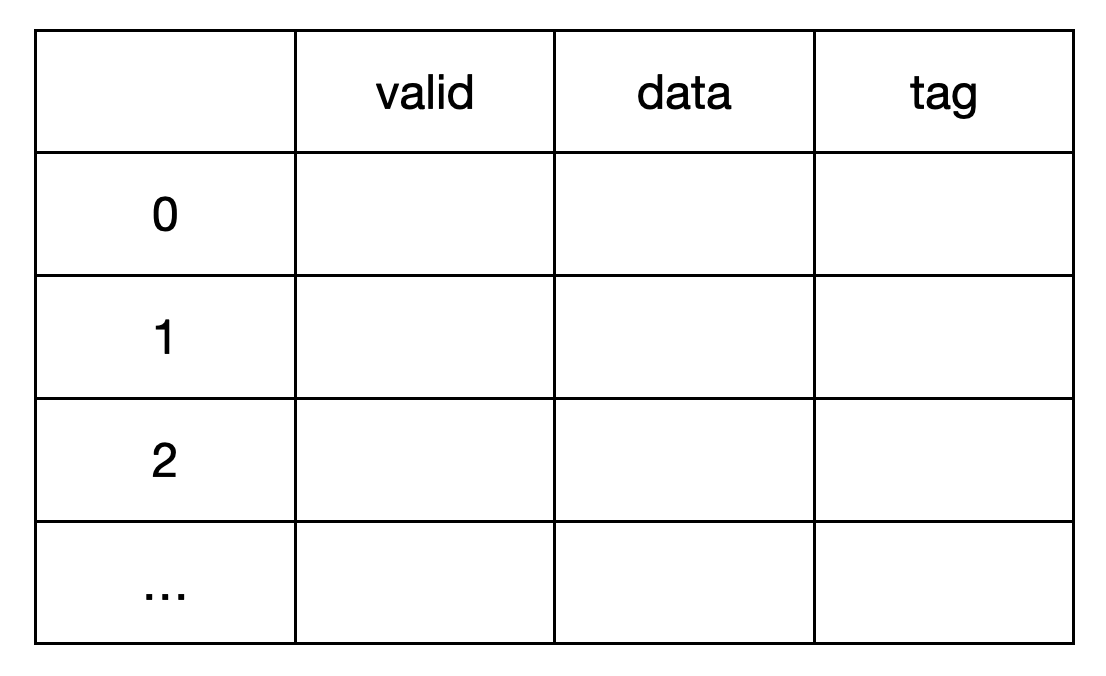
여러 방법이 있겠지만, Scoreboard에 valid bit와 함께 어떤 명령어에 의해 가장 최근 Book 되었는지 확인하거나, valid bit를 단일 비트가 아닌 현재 쓰기가 진행 중인 처리 명령어의 개수를 기억하고 release 할 때마다 이 값을 하나씩 줄일 수 도 있을 것 같다. 전자의 경우 writeBack 단계에서 release시 Reg의 tag가 명령어의 tag와 일치하는지 확인하는 것으로 아직 쓰기가 끝나지 않은 다른 명령어가 있다는 것을 확인하는 것이고, 후자의 경우 처리 명령어의 개수가 0이 아닌지를 확인하는 것으로 아직 쓰기가 끝나지 않은 다른 명령어가 있음을 확인한다.
Stall
데이터 의존이 있는 경우(data hazard) 또는 분기가 존재하는 경우, 의존이 없어지거나 분기 여부가 결정될 때까지(control hazard) delay 시키는 것이 가장 편한 솔루션일 것이다. 처리되어야 하는 명령어의 처리 사이클은 동일하고, 그 앞 단계의 유효하지 않은 명령어의 controlSignal에 valid 비트를 추가하여 invalid의 경우 MemoryAccess와 WriteBack 단계를 무시하면 된다. 가장 간단한 Hazard 해결 방안이면서도 사이클이 매번 늘리기 때문에 비효율적이다.
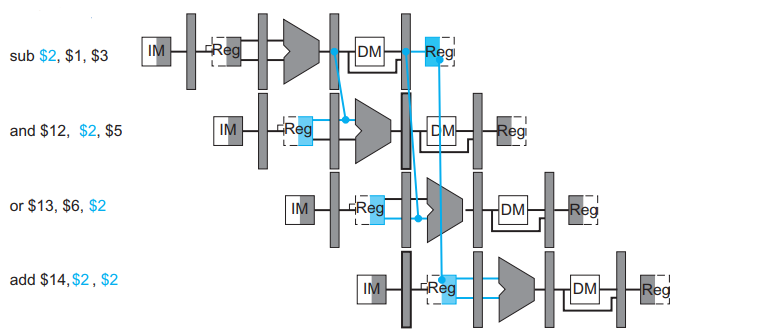
Forwarding
writeBack에 저장될 값이 결정되는 시점의 값을 미리 앞 당겨, ALU에서 처리를 마친 결괏값 또는 MemoryAccess 단계에서 메모리를 읽은 값을 직접 ALU에 들어갈 input으로 대입하는 방식이다. 단, LW 이후에 바로 레지스터가 겹칠 경우 4단계에서 결정되는 레지스터 값을 같은 사이클에서, 즉 바로 다음 이어지는 명령어의 ALU의 인풋으로 할 수 없기 때문에 아래와 같이 하나의 stall은 피할 수 없다.
Branch prediction
분기 결과를 execution stage의 실제 계산을 통한 값이 아닌, 예측 전략에 의한 결과로 생각하고 다음 pc 값을 결정하는 것을 말한다. execution 단계에서 계산한 분기 결과가 예상한 결과와 일치하면, 적어도 한 개에서 두 개의 무의미한 명령어를 실행하지 않아도 되고, 이는 곧 한개에서 두개의 사이클 이득을 볼 수 있다는 말이 된다.
반대로 분기 결과가 예상한 결과와 일치하지 않는다면 예측에 의해 미리 fetch 된 한, 두 개의 명령어가 무의미해지는 것은 같으나, 예측의 실패를 분기 예측 전략에 반영하여 다음번 분기 예측의 가능성을 높인다.
분기 예측에 의해 이득을 볼 수 있는 사이클의 개수는 Branch prediction 방식에 따라 달라진다. decode 단계에서 해당 명령어가 분기 명령어임을 확인한 후 분기 예측이 진행되는 경우에는 fetch 단계에 관련 없는 명령어가 이미 실행되고 있는 경우이므로, execution 단계에서 분기 결과를 확인한 후 분기가 처리되는 경우보다 한 개의 사이클 이득을 얻을 수 있다. 또는 이전 분기 결과를 담은 버퍼를 사용하여, fetch 단계에서 pc 값을 통해 분기 명령을 확인하고 분기 예측이 진행되는 경우, 분기 예측을 진행하지 않는 경우보다 두 개의 사이클 이득을 얻을 수 있는 것이다.
Static Branch Prediction
분기를 예측하는 전략이 정적인 방식을 말한다. 이 전략으로 해당 분기 명령어가 분기될지, 안될지를 예측하게 된다. 예를 들면 항상 분기가 일어난다고 예측하는 전략인 Always taken, 반대로 항상 분기가 일어나지 않는다고 예측하는 전략인 Always not taken, 분기의 방향이 후방인 경우에는 분기가 일어남을, 전방인 경우에는 분기가 일어나지 않는다고 예측하는 전략인 BTFNT(Backward taken, Forward not taken) 등이 있다.
Dynamic Branch Prediction
분기를 예측하는 전략이 예측과 검증이 진행되면서 이전 예측 성공 여부가 다음 예측에 반영되는 방식을 말한다. 대표적으로 bit counter를 이용하여 이전 결과가 다음번 예측에 반영될 수 있도록 할 수 있다. 대표적인 1bit counter 방식, 2bit counter 방식을 소개한다.
1. single bit counter prediction

2. Saturation two bit counter prediction
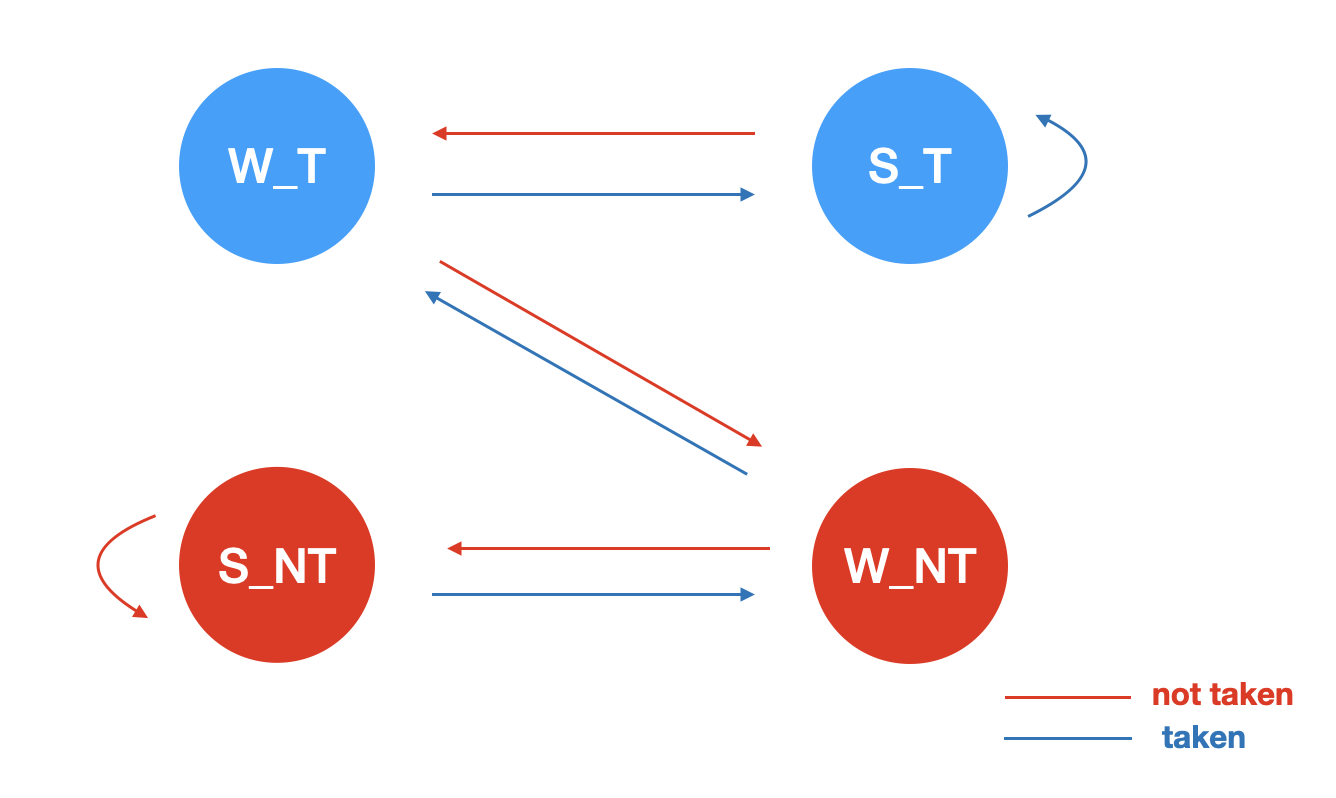
3. Hysteresis two bit counter prediction
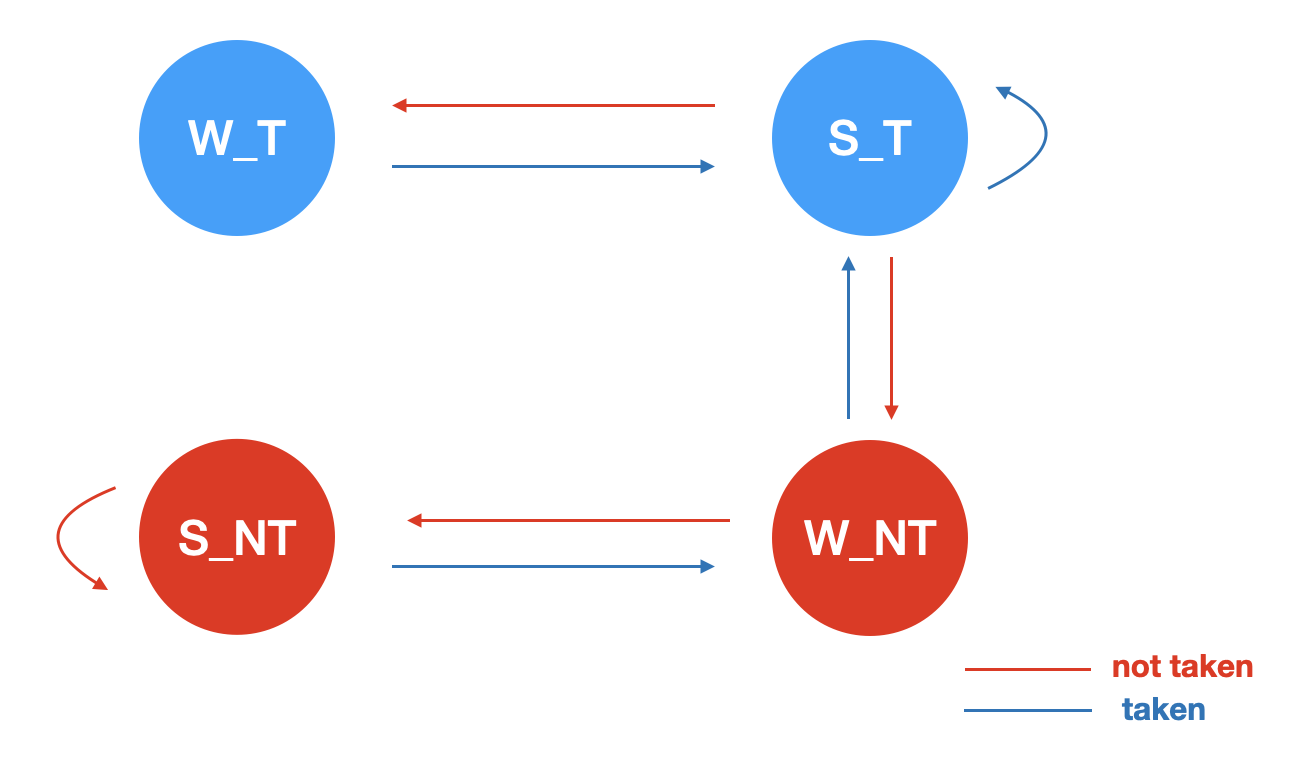
Branch target buffer
명령어가 분기 예측되려면 명령어가 우선 해석되어야 한다. 해당 명령어가 분기 명령어인지 확인해야 하고, 분기하고자 하는 다음 pc 값을 decode 단계에서 해석해야 한다. 만일 명령어가 분기 명령어가 맞으면 분기 예측을 실행하고 taken으로 예측된다면 해석한 nextPc를 다음 fetch의 pc로 사용한다. 이때 이득을 볼 수 있는 사이클은 1개이다.
만약 decode 단계가 아닌 fetch 단계에서 분기 예측이 될 수 있다면 어떨까. fetch 단계에서 바로 분기 예측을 실행하고 바로 다음 사이클의 fetch에 그 결과를 사용할 수 있어진다. taken으로 예측된다고 하고, 그 예측이 맞다면 execution 단계에서 결과를 예측하는 것보다 두 개 사이클의 이득을 볼 수 있어진다.
Branch target buffer는 pc만을 이용하여 분기 예측을 하기 위해 사용하는 버퍼이다. 분기 명령어의 pc값과 target pc값을 저장하고 다음번에 같은 pc가 수행될 때 그 값을 참고하여 분기 예측할 수 있어진다.
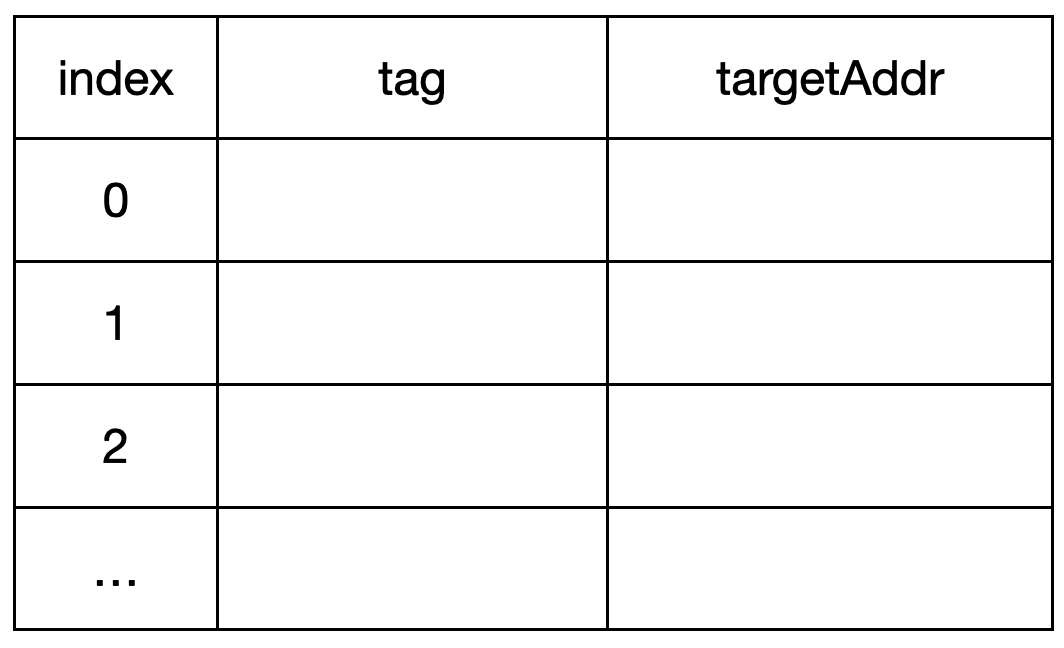
이때 모든 pc 값을 다 담을 수 없기 때문에, 또 그렇다고 index가 존재하지 않아 모든 buffer line을 매번 탐색할 수 없기 때문에 index와 tag를 이용한다. pc 주소의 일정 부분을 index로, 나머지 부분을 tag로 한다. 이후 다른 pc가 들어왔을 때 index에 해당하는 tag 데이터를 비교하여 해당 인덱스에 같은 명령어 정보가 존재하는지 확인하는 식으로 hit/miss를 결정할 수 있다.
Two-level global history branch predictor
프로그램에서 조건문이 연속되고 이들이 서로 의존적인 경우처럼, 특정 명령어의 기록이 아닌 최근에 실행된 분기 명령어의 전역적인 행동의 기록을 Global branch history라고 한다.
예를 들어 어떤 프로그램의 가장 최근 분기가 Taken -> Not Taken -> Taken -> Taken이라고 하자. 이 패턴이었을 때 분기 여부를 기록하고 다음번에 같은 패턴의 분기가 발생할 경우 이전 기록과 같은 분기 결과로 예측할 수 있는 것이다. 이를 테면 single bit counter prediction 전략을 사용하는 상황에서, 기존에 TNTT의 분기 결과가 T이면 다음번 TNTT 분기 결과를 T으로 예상하고, 틀릴 경우에는 다음번 TNTT에서 F를 예상하는 것이다.
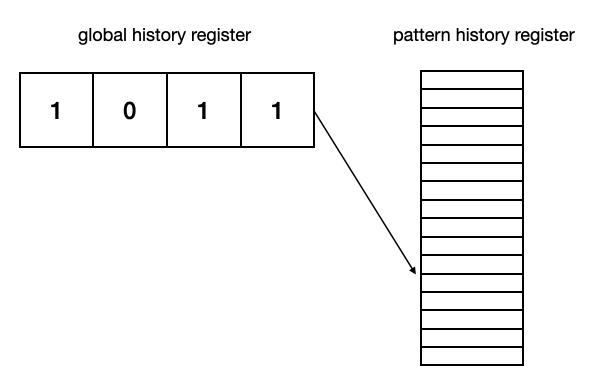
어떤 분기 패턴에서 기존에 어떤 분기 예측 결과가 있었는지 저장하기 위해 pattern history register가 필요하다. global history register의 n개 비트를 인덱스로 하는, 즉 2^n개의 라인 수를 갖고 있는 분기 예측 결과표가 필요한 것이다. 위의 예시라면 Pattern history register는 총 16개의 라인이 있을 것이고, single bit counter prediction을 사용하기 때문에 매 라인마다 1bit씩 이전 분기 예측 결과를 저장하게 되는 것이다. 물론 two bit counter prediction도 문제없다. pattern history register의 각 라인이 2bit씩 할당되어, strongly taken/weakly taken/weakly not taken / strongly not taken을 저장하면 되는 것이다.

Global history register와 branch target buffer를 결합하여 최근 4개 분기 결과에 따른 분기 예측 / Next pc를 얻는 구조는 위와 같다. 이를 Two-level Global history branch predictor라고 한다.
Two-level local history branch predictor
Global history와 반대로 특정 명령어에 따른 행동을 기록하고 이 패턴을 통해 분기 예측한다. 예를 들어 이전에 TNTTNT 패턴의 경우 항상 다음은 T으로 이어졌다고 가정해보자. 특정한 pc의 이전 분기 기록이 TNTTNT이라면 다음은 역시 T일 가능성이 크다. 전체 프로그램의 분기 패턴만을 기록하는 Global history branch predictor에선 이 예측을 놓치기 쉽다. Global history branch predictor는 프로그램 전체의 분기 패턴을 기록한다면, Local history branch predictor는 반대로 명령어마다의 이전 분기 패턴을 기록하여 예측에 활용하는 방식이다.
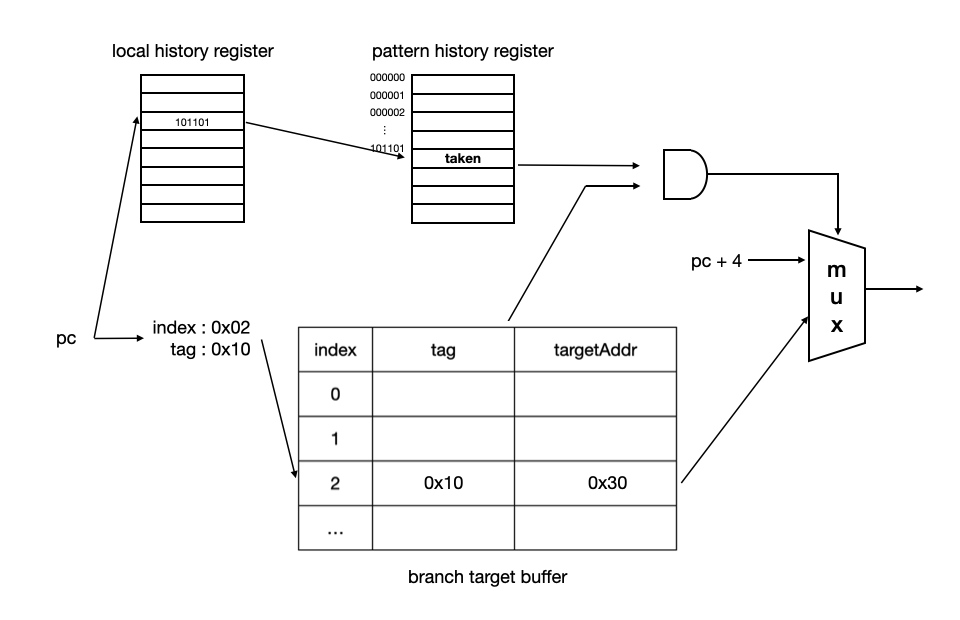
그렇다고 Local history 기반의 예측이 Global history 기반의 예측보다 더 우세한 것은 아니다. 상황에 따라 우세한 global/local history 예측기가 다르고, 우세한 saturation/hysteresis bit counter 전략이 다르다. 따라서 최근에는 여러 예측기를 바꿔가며 서서히 성능을 올려보거나, 분기마다 다른 예측기를 사용하고 결과를 확인하는 등의 방식으로 예측기를 선택한다.
1. Code work / Implementation
구현한 내용은 다음과 같다.
ControlUnit
- 단일 프로그램을 싱글사이클로 처리할 수 있다.
- 단일 프로그램을 멀티사이클 / 파이프라인으로 처리할 수 있다.
- DataHazard를 Stalling으로 처리한다.
- DataHazard를 Forwarding으로 처리한다.
- 여러 프로그램을 멀티사이클/파이프라인으로 처리한다.
ProgramCounter
- 분기 예측 없이 Stalling만으로 분기 명령어를 처리할 수 있다.
- 분기 예측 전략에 따른 정적 분기 예측을 수행할 수 있다.
- 분기 예측 전략에 따른 동적 분기 예측을 수행할 수 있다.
- Branch Target Buffer를 이용한 분기 예측을 수행할 수 있다.
- Local history register와 Pattern history register를 이용한 분기 예측을 수행할 수 있다.
- Global history register와 Pattern history register를 이용한 분기 예측을 수행한다.
BranchPredictionStrategy
- 분기 예측 전략을 지정할 수 있다.
- Always taken으로 예측하는 전략을 정의한다.
- Always not taken 으로 예측하는 전략을 정의한다.
- Backward taken, Forward not taken 예측하는 전략을 정의한다.
BitStateMachine
- N bit를 이용하여 예측 성공 여부가 다음 예측에 반영될 수 있는 상태 머신을 정의한다.
- 단일 비트로 예측하는 상태 머신을 정의한다.
- Saturation two bit counter 예측을 위한 2 bit 상태 머신을 정의한다.
- Hysteresis two bit counter 예측을 위한 2 bit 상태 머신을 정의한다.
HistoryRegister / Branch Target Buffer
- 분기 결과를 저장할 수 있다.
- 최근 n번의 지역 분기 결과를 저장할 수 있는 Local history register를 정의한다.
- 최근 n번의 전역 분기 결과를 저장할 수 있는 Global history register를 정의한다.
- 최근 분기 결과마다의 예측 결과 패턴을 저장할 수 있는 Pattern history register를 정의한다.
- pc의 분기 내용을 캐싱할 수 있다.
- pc로 인덱싱 된 Branch target buffer를 정의한다.
2. Class diagram
전체 클래스 다이어그램은 다음과 같다. PipeLine 방식, Control Hazard, Data Hazard를 해결할 수 있는 다양한 전략들을 추상화하고, 테스트에서 그 구현체를 변경하는 것으로 각 전략에 따른 효율성을 쉽게 비교할 수 있도록 설계하고자 노력하였다.
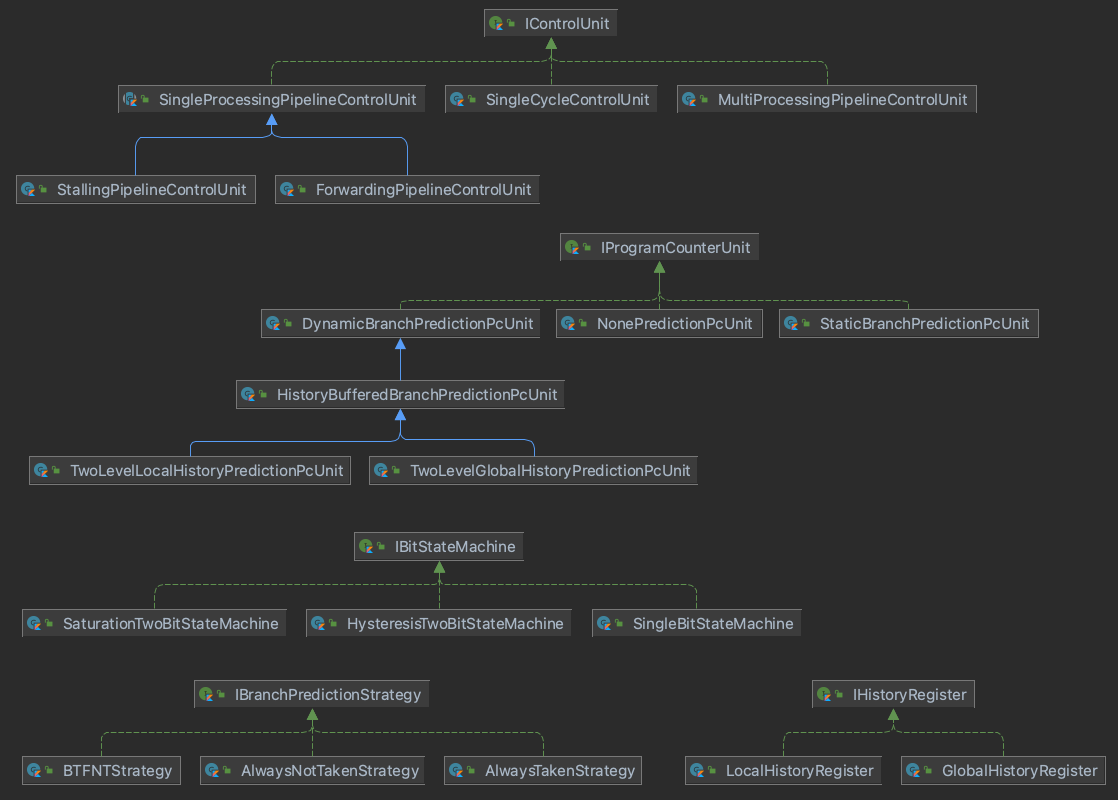
3. ControlUnit
3-1. SingleProcessingPipelineControlUnit
단일 프로그램을 파이프라인으로 처리하는 방식의 5단계를 추상 클래스로 묶는다. Data Hazard, Control Hazard를 처리하는 방식의 다양함과는 상관없이 기본 fetch, decode, execute, memoryAccess, writeBack 단계의 내용은 동일하다.
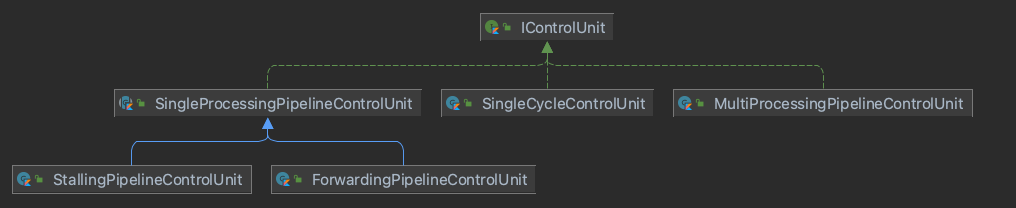
이후 단일 프로그램을 파이프라인으로 처리하는 구현체는 이를 상속하고 앞선 5단계를 어떻게 수행할지 결정하는 cycleExecution()만을 재정의하는 것으로 파이프라인 ControlUnit을 정의할 수 있다.
abstract class SingleProcessingPipeLineControlUnit(
private val memory: Memory,
) : IControlUnit {
protected val registers: Registers = Registers(32)
protected val stallUnit = StallUnit()
protected val latches = Latches()
private val decodeUnit = DecodeUnit()
private val alu = ALUnit()
abstract fun cycleExecution(valid: Boolean, pc: Int): CycleResult
override fun process(): List<Int> { .. }
fun fetch(valid: Boolean, pc: Int): FetchResult { .. }
fun decode(ifResult: FetchResult): DecodeResult { .. }
fun execute(idResult: DecodeResult): ExecutionResult { .. }
fun memoryAccess(exResult: ExecutionResult): MemoryAccessResult { .. }
fun writeBack(maResult: MemoryAccessResult): WriteBackResult { .. }
}
3-2. ForwardingPipeLineControlUnit
아래는 forwarding을 이용하여 DataHazard를 피하도록 설계한 ControlUnit이다. 한 사이클에서 다섯 단계가 동시에 처리되면서, Latch를 이용하여 이전 사이클의 결과를 다음 사이클의 다음 단계로 넘기는 구조를 기본으로 한다. 여기에 ForwardingUnit이 execution 단계 전에 이전 사이클의 출력 값을 확인하여 dataFowarding을 처리한다.
pcUnit은 ProgramCounterUnit 인터페이스를 타입으로 하여, 어떤 PcUnit 구현체로도 쉽게 바꿀 수 있도록 하였다. 예를 들어 pcUnit을 NonePrediction으로 한다면 branchPrediction 없이 stalling만으로 controlHazard를 처리하도록, DynamicBranchPredictionPcUnit을 구현체로 한다면 동적 분기 예측 전략을 다시 선택하여 해당 전략으로 pc를 얻을 수 있도록 구현하여 변화와 전략에 유연한 코드를 만들고자 하였다.
class ForwardingPipelineControlUnit(
memory: Memory,
private val pcUnit: IProgramCounterUnit = NonePredictionPcUnit()
) : SingleProcessingPipelineControlUnit(memory) {
private val forwardingUnit = ForwardingUnit()
override fun cycleExecution(valid: Boolean, pc: Int): CycleResult {
val prevIfId = latches.ifId()
val prevIdEx = latches.idEx()
val prevExMa = latches.exMa()
val prevMaWb = latches.maWb()
val wbResult = writeBack(prevMaWb)
val nextMaWb = memoryAccess(prevExMa)
forwardingUnit.forward(prevIdEx, prevExMa, prevMaWb)
val nextExMa = execute(prevIdEx)
val nextIdEx = decode(prevIfId)
val nextIfId = fetch(valid, pc)
val nextPc = pcUnit.findNext(pc, nextIfId, nextIdEx, nextExMa)
latches.store(nextIfId)
latches.store(nextIdEx)
latches.store(nextExMa)
latches.store(nextMaWb)
return CycleResult(
nextPc = nextPc,
value = registers[2],
valid = wbResult.valid,
isEnd = nextPc == -1,
lastCycle = wbResult.controlSignal.isEnd
)
}
}
3-3. StallingPipelineControlUnit / Scoreboard
모든 DataHazard를 Stalling으로 처리하였다. 기본적인 PipeLine 구조는 앞선 ForwardingPipelineControlUnit과 동일하나, DataDependency를 확인하는 방식을 Scoreboard를 이용하여 읽고자 하는 레지스터가 아직 '쓰기'를 완료하지 않은 레지스터인지 확인하는 과정이 추가되어 있다. '쓰기' 명령어는 반대로 write 할 레지스터를 decode 단계에서 예약하고, 쓰기가 완료되면 tag를 확인하여 동일하면 해당 레지스터를 이제는 읽어도 좋은 valid 상태로 표시한다.
class Scoreboard(
size: Int
) {
private val valid: Array<Boolean> = Array(size) { true }
private val tag: Array<Int> = Array(size) { 0 }
fun book(regWrite: Boolean, writeRegister: Int, tag: Int) {
if (regWrite && writeRegister != 0) {
this.valid[writeRegister] = false
this.tag[writeRegister] = tag
}
}
fun release(writeRegister: Int, tag: Int) {
if (this.tag[writeRegister] == tag) {
this.valid[writeRegister] = true
}
}
fun isValid(writeRegister: Int): Boolean {
return this.valid[writeRegister]
}
}
4. MultiProcessingPipelineControlUnit
Pipeline에서 각 단계에 서로 다른 프로그램이 처리된다면, 그리고 register와 memory가 각 프로세스마다 분리되어 있다면 dataHazard와 controlHazard를 고민하지 않아도 되겠다는 아이디어에서 다중 프로그램을 처리할 수 있는 pipelined control unit을 간단히 구현해보았다.
구현한 MultiProcessingPipelineControlUnit은 프로그램마다 서로 다른 ControlRegister를 갖고 있고, SchedulingUnit이 사이클 시작 시 처리할 프로그램 번호와 pc, 끝나면 해당 사이클의 writeBack 결과를 프로그램 번호에 해당하는 controlRegister에 반영하도록 하였다.
class MultiProcessingPipelineControlUnit(
private val memories: List<Memory>
) : IControlUnit {
private val registers: List<Registers> = List(memories.size) { Registers(32) }
private val schedulingUnit = SchedulingUnit(memories.size)
override fun process(): List<Int> {
var cycle = 0
Logger.init()
while (!schedulingUnit.isAllEnd()) {
val programInfo = schedulingUnit.next()
val isProcessEnd = programInfo.processEnd
val cycleResult = cycleExecution(!isProcessEnd, programInfo.pn, programInfo.nextPc)
schedulingUnit.update(cycleResult)
latches.flushAll()
cycle++
}
return registers.map { it[2] }.toList()
}
...
}
더 보완하고 싶은 부분은 다음과 같다.
4-1. SchedulingUnit의 처리 프로세스 순서
구현한 SchedulingUnit은 Round Robin 방식으로 순차적으로만 프로세스를 받아 처리하고 있다. SchedulingUnit이 처리 프로세스를 결정하는 과정을 분리하여, 정의한 알고리즘에 따라 프로세스의 처리 우선순위를 고려하여 할 수 있는 스케줄링 방식으로 확장하고 싶다.
fun next(): ProgramInfo {
for (i in 0..size) {
lastProcessIndex = (lastProcessIndex + 1) % size
if (programNumbers[lastProcessIndex].alive) {
return programNumbers[lastProcessIndex]
}
}
throw IllegalArgumentException("No process to fetch")
}
4-2. 동적으로 Dependency 처리 방식 결정
현재 구조에선 dataHazard를 무시하고 있다. Data dependency 조건은 명령어 간 거리가 2 이하로 같은 프로세스의 거리가 1 또는 2인 경우 dataHazard가 발생하고, 따라서 동시에 실행되는 프로세스는 반드시 3개 이상이어야만 한다.
구현한 MultiProcessingPipelineControlUnit은 프로세스가 종료되면 해당 프로세스는 더 이상 스케줄링하지 않도록 하였다. 다만 앞선 Data denpency 거리 조건의 문제로 남은 프로세스가 3개 이하일 때는 좀비 프로세스(무조건 Nop으로 처리되는 프로세스)로 처리하고 있다. 즉 1개 프로세스만 실행된다고 하더라도 나머지 두 개는 Stalling을 위하여 3개의 프로세스가 동시에 처리되고 있는 비효율이 존재한다.
따라서 프로세스 남은 개수에 따라 동적으로 ControlUnit의 Hazard 처리 방식이 달라질 수 있도록 보완해야 한다.
5. ProgramCounterUnit
5-1. 클래스 다이어그램은 다음과 같다.
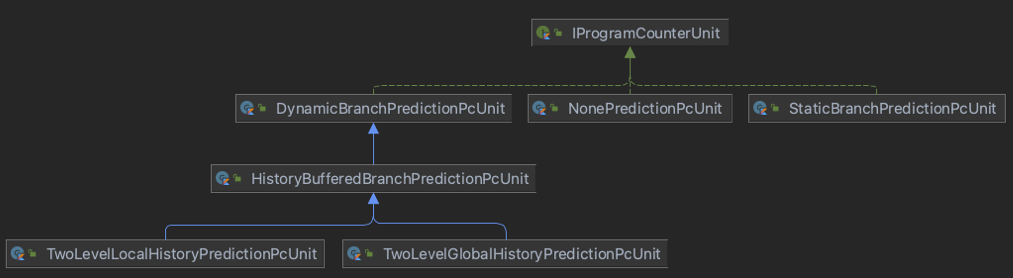
pc를 계산하는 방식에서, Branch Prediction을 진행하지 않는 NonePredictionPcUnit, 정적 예측을 진행하는 StaticBranchPredictionUnit, 동적 예측을 진행하는 DynamicBranchPredictionUnit, 그 아래 HistoryBuffer를 사용한 경우와 사용하지 않은 경우를 또 따로 분리하여 구현하였다.
이를 통해 ControlUnit에 원하는 ProgramCounter 방식과 예측 전략을 조립할 수 있었다. 아래는 DataHazard와 ControlHazard를 해결하는 방식을 각각 달리 조합하여 ControlUnit을 조합한 예시이다.
// DataHazard = forwarding, ControlHazard = stalling
val pcUnit = NonePredictionPcUnit()
val controlUnit = ForwardingPipelineControlUnit(memory, pcUnit)
// DataHazard = stalling, ControlHazard = twoLevelGlobalHistoryBranchPrediction
val pcUnit = TwoLevelGlobalHistoryPredictionPcUnit()
val controlUnit = StallingPipelineControlUnit(memory, pcUnit)
// DataHazard = forwarding, ControlHazard = BTFNT_branchPrediction
val predictionStrategy = BTFNTStrategy()
val pcUnit = StaticBranchPredictionPcUnit(predictionStrategy)
val controlUnit = ForwardingPipelineControlUnit(memory, pcUnit)
5-2. Branch Target Buffer
Branch Target Buffer은 valid bit, tag bit, targetAddress로 구성하였다. pc의 가장 마지막 2비트를 제외하고 buffer의 line 사이즈만큼의 하위 비트를 index, 나머지 상위 비트를 tag로 한다. 아래 예시는 구현한 branch target buffer에 pc가 0x0000:0B3F, bufferLine이 16, lineIndex가 15인 경우이다.
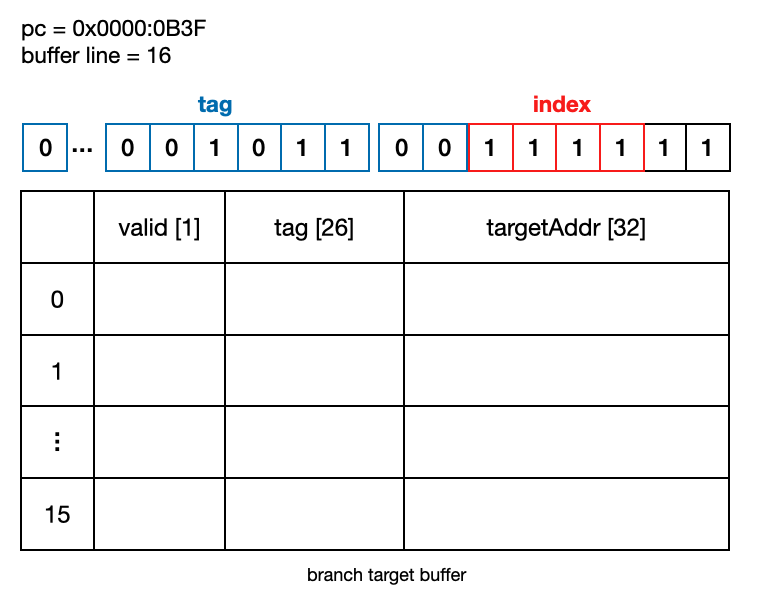
pc의 index부로 buffer line을 찾고 해당 line의 tag와 pc의 tag부가 일치하는 경우를 hit로 한다. valid bit는 해당 line의 tag 값이 더미 값인지 아닌지를 구분하기 위해서 사용한다. 예를 들어 tag 초기 값이 모두 0인 경우에 pc의 tag가 0이라면 이 경우 hit -> targetAddress를 믿을 수 있는 것인지, 혹은 tag가 초기 값이라 targetAddress 역시 초기 값으로 hit가 아닌 상황인지 모른다. 이 상황을 피하기 위해 valid bit를 두고 초기 값을 false로 하였다.
class BranchTargetBuffer(
val size: Int
) {
private val valid = Array(size) { false }
private val tags = Array(size) { 0 }
private val targetAddresses = Array(size) { 0 }
fun update(pc: Int, targetAddress: Int) {
val index = index(pc)
valid[index] = true
tags[index] = tag(pc)
targetAddresses[index] = targetAddress
}
fun targetAddress(pc: Int): Int {
val index = index(pc)
return targetAddresses[index]
}
fun isHit(pc: Int): Boolean {
val index = index(pc)
return valid[index] && tags[index] == tag(pc)
}
private fun index(pc: Int): Int {
return (pc / 4) % size
}
private fun tag(pc: Int): Int {
return (pc / 4) / size
}
}
6. Logger
6-1. Pipeline Logger
디버깅 편의를 위해 기존의 Logger를 상속하여 Pipeline 전용 로거를 만들어 보았다. 기존의 Single cycle 구현에서 만든 Logger를 Pipeline 프로세서에서 사용하면 아래와 같이 각 단계마다 모두 다른 pc에 해당하는 로그를 출력하고, 경우에 따라 한 pc에 해당하는 5단계 진행을 보고 싶은 경우가 잦았다.
fun log(
fetchResult: FetchResult,
decodeResult: DecodeResult,
executionResult: ExecutionResult,
memoryAccessResult: MemoryAccessResult,
writeBackResult: WriteBackResult
) {
cycleLogs[0].fetchResult = fetchResult
cycleLogs[1].decodeResult = decodeResult
cycleLogs[2].executionResult = executionResult
cycleLogs[3].memoryAccessResult = memoryAccessResult
cycleLogs[4].writeBackResult = writeBackResult
printCycleLog(
fetchResult = cycleLogs[4].fetchResult,
decodeResult = cycleLogs[4].decodeResult,
executionResult = cycleLogs[4].executionResult,
memoryAccessResult = cycleLogs[4].memoryAccessResult,
writeBackResult = cycleLogs[4].writeBackResult
)
flushCycleLog()
}한 사이클의 모든 단계 로그를 담을 수 있는 CycleLog를 5개 배열로 정의하고 사이클 시 종료마다 이 사이클에서 얻은 5단계의 로그를 채워 다시 다음 배열로 넘긴다(flushCycleLog). 2단계뿐이었던 latch를 5단계로 늘려 5개 사이클의 로그를 저장하는 원리이다. 그리고 5번째 배열을 매 사이클마다 출력하면 한 pc에서 얻은 5단계의 로그를 확인할 수 있는 것이다.
추가로 이때 stalling이 어떻게 추가되었는지, jump가 어떻게 되었는지에 따라 각 단계의 pc가 다를 수 있다. 출력 시에는 모든 단계의 결과 값이 valid 한 지, 각 단계의 pc값이 같은지를 확인해야 한다.
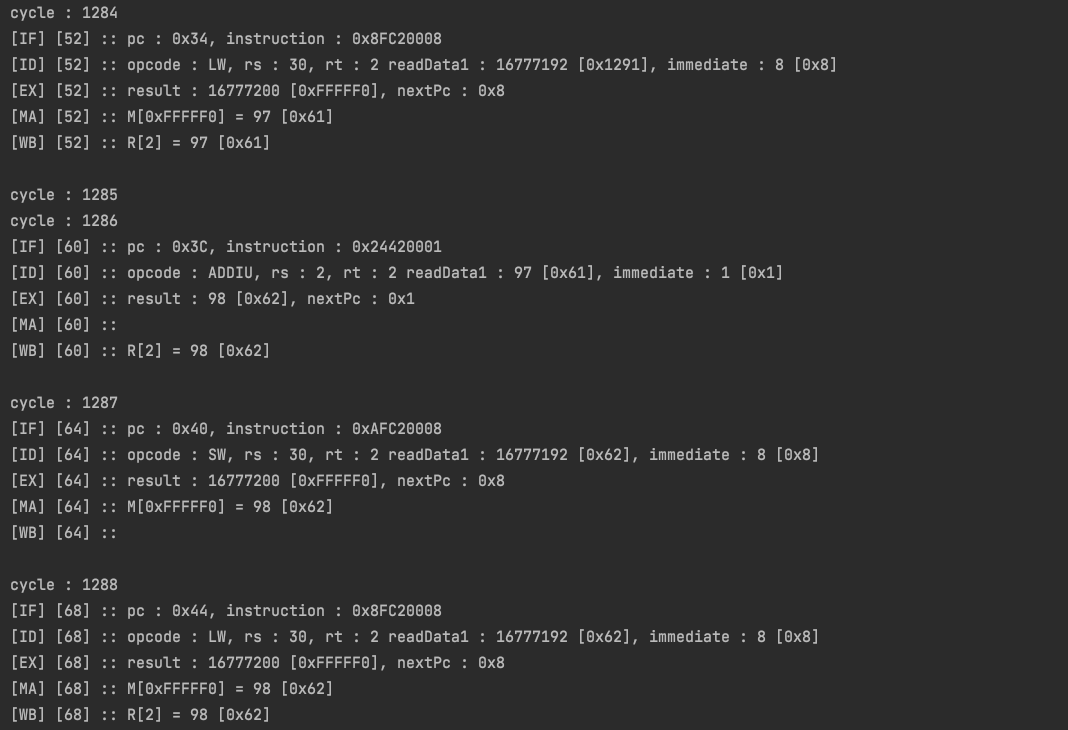
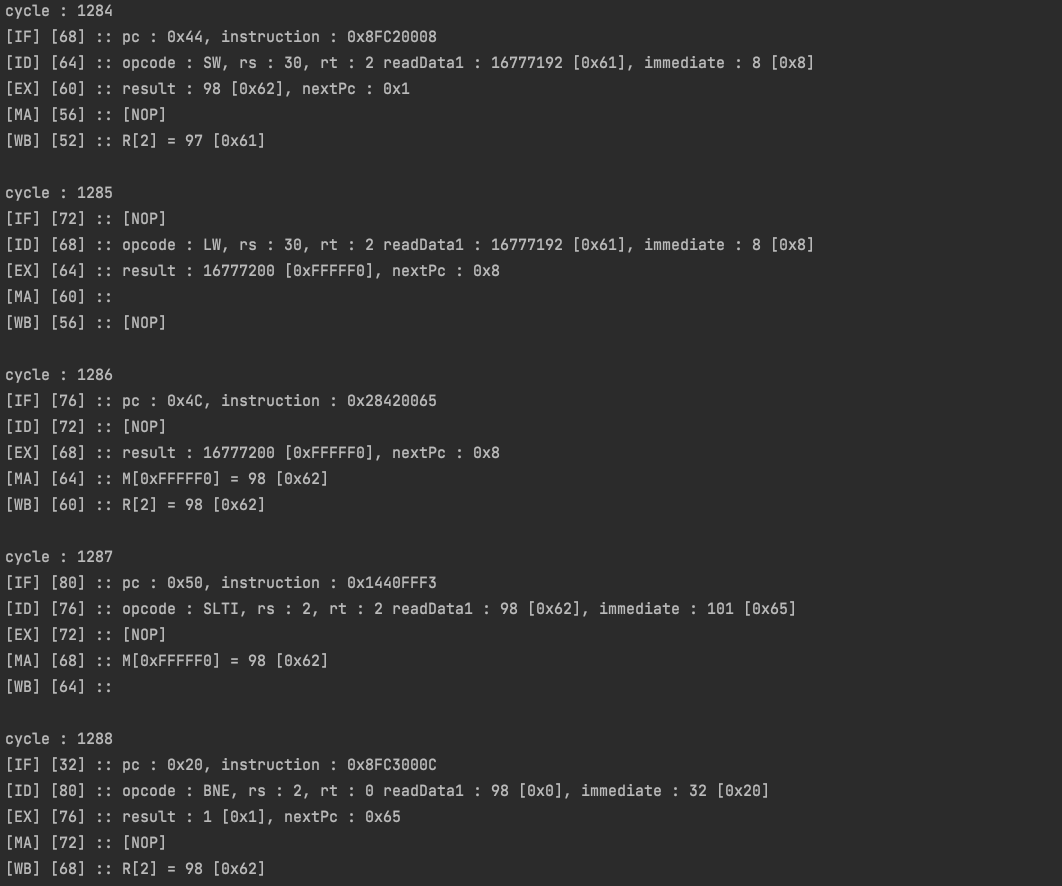
위 로그는 이번에 구현한 Pipeline Logger를 이용한 출력이고, 아래는 일반 Logger를 이용한 출력이다. 로그 시작 부분 단계 옆, 대괄호의 숫자가 해당 로그의 pc를 가리킨다.
6-2 LoggingSignal
특정 프로그램은 사이클이 너무 많아 출력된 로그를 모두 확인하는데 문제가 있었다. 로그를 모두 출력하면 해당 프로그램을 실행하는 데에도 오래 걸리고, 너무 많은 정보에 어떤 부분을 중점으로 봐야 하는지도 헷갈려진다. 또는 반대로 특정 부분은 천천히 출력하여 해당 부분을 눈으로 확인하고 싶은 경우도 있었다.
LoggingSignal을 구현하여 로그 출력의 설정을 관리하였다. 아래 코드에서 cycle부터 result는 해당 옵션이 출력될 것인지를 결정한다. cyclePrintPeriod는 출력되는 사이클의 주기를 표시한다. 아래 예시에서는 cycle은 출력을 하되 1000개마다 한 번씩 출력하고, memoryAccess와 writeBack 단계의 로그만을 출력한다.
sleepTime 출력 시간을 결정한다. 값 1000을 1초로 하여 300으로 값을 설정할 경우 매 출력마다 0.3초의 딜레이를 준다. from, to는 출력의 시작 사이클과 끝 사이클을 지정하는 것이다. 이런 LoggingSignal 외에도, 코드 안에 여러 로깅 설정을 추가하여 조금이라도 더 편하게 디버깅할 수 있는 방법을 고민하였다.
val loggingSignal = LoggingSignal(
cycle = true,
fetch = false,
decode = fasle,
execute = false,
memoryAccess = true,
writeBack = true,
result = true,
cyclePrintPeriod = 100,
sleepTime = 3000,
from = 2000,
to = 3000
)
7. Test Result
0. 대상 프로그램은 Simple3, Simple4, GCD, Fib, Input4로 하였다.
1. Multi-Cycle : Single-cycle의 처리 명령어 종류와 개수를 바탕으로 Multi-cycle로 실행하였을 경우의 cycle count를 계산하였다.
2. Branch Target Buffer : buffer 라인을 16으로 하는 944bit 크기의 buffer를 사용하였다.
3. Local History Register : 최근 4개의 지역 Branch 여부 history를 저장하고, Buffer 라인은 16으로 하였다.
4. Global History Register : 최근 4개의 전역 Branch 여부 History를 저장하였다.
5. 2 Level History Prediction의 PatternHistory 전략은 Saturation 2bit counter를 사용하였다.
6. Multi Processing n process avg : 동일한 프로그램을 n개 동시 처리하고 각 cycle count를 평균 내었다.
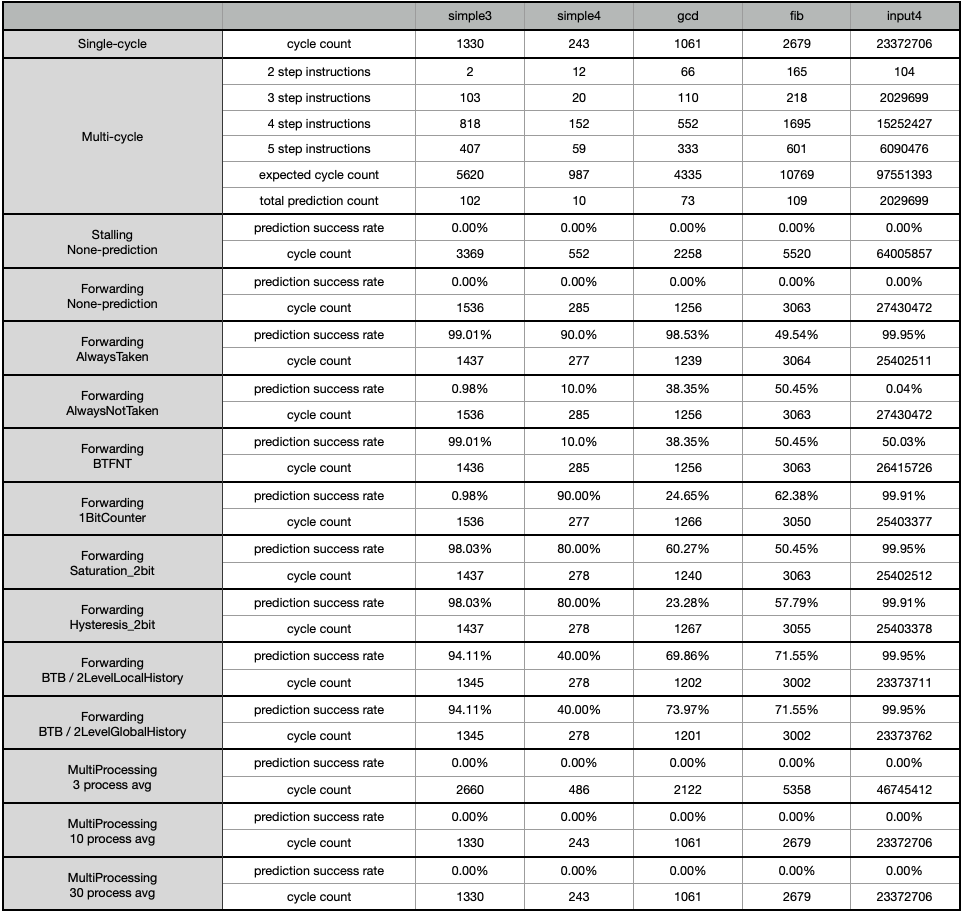
multi-cycle에 비해 pipelining으로 얻은 성능 증가 순위와 사이클 개선율은 다음과 같다.
1. Multi-Processing (317.373123%)
2. Forwarding-2LevelLocalHistory (317.355177%)
3. Forwarding-2LevelGlobalHistory (317.354266%)
4. Fowarding-alwaysTaken (284.022638%)
prediction도 없고, 스케줄링도 제대로 안 되는 간단히 만들어 본 Multi-processing control unit이었지만, 처리하는 프로세스의 개수가 일정 개수 (input4 기준, 5개) 이상인 상황에서 다른 방식들보다 월등한 성능 차이를 내었다.
alwaysTaken, alwaysNotTaken, BFTNT, 1bit counter, 2bit counter 등, 예제 프로그램의 개수가 적고, 내용이 짧아 BranchPrediction 전략에 따른 성능 차이를 명확하게 보긴 어려웠다. 프로그램이 좀 더 길고 다양한 분기 상황들이 더 많아야 예측 전략 비교가 가능할 것이라고 생각한다.
다만 Pipelining, Forwarding, BranchPrediction, Branch target buffer 등 구조적인 부분에서의 발전과 성능 차이는 명확히 확인할 수 있었던 테스트였다고 생각한다.
16개의 서로 다른 구조, 전략으로 총 100개의 테스트를 작성하였고 위 표는 성능 비교를 위해, 그중 일부만을 표시하였다. 테스트 상세 내용과 결과 확인을 위해 아래 테스트 결과 파일을 첨부한다.

'Computer Science > Computer architechture' 카테고리의 다른 글
| CPU와 메모리 사이의 명령어 캐시, 구현과 성능 개선 (0) | 2022.06.11 |
|---|---|
| 싱글사이클 기반 MIPS 프로세서 설계 (0) | 2022.04.24 |
| 캐시의 개념과 종류 / 쓰기 정책과 교체 정책 (0) | 2019.07.05 |
| 명령어 파이프라이닝 / Forwarding과 분기 예측 (0) | 2019.07.01 |
| 프로세서/ single cycle, multi cycle / 싱글 사이클, 멀티 사이클 (0) | 2019.06.28 |