
ecsimsw
프로세서/ single cycle, multi cycle / 싱글 사이클, 멀티 사이클 본문
프로세서/ single cycle, multi cycle / 싱글 사이클, 멀티 사이클
JinHwan Kim 2019. 6. 28. 14:59
Single-Cycle processor
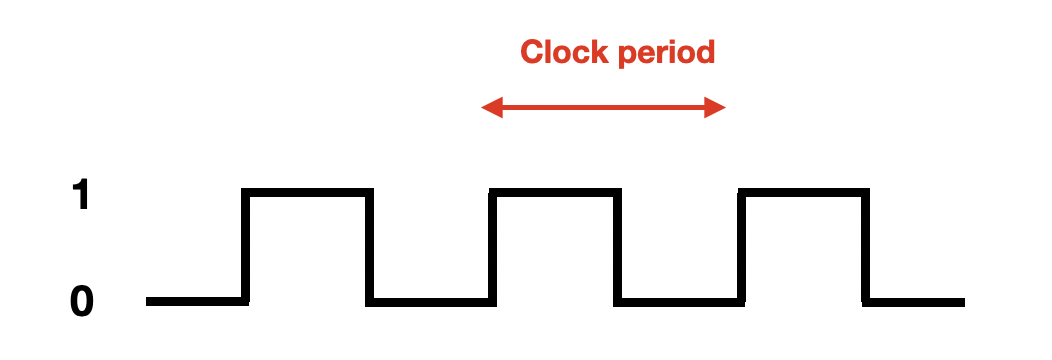
CPU는 내부 회로를 동작시키기 위해 일정한 주기로 규칙적인 전기 신호를 발생시키는데 이를 Clock이라고 한다. 즉 1 clock cycle은 한 번의 전기 신호를 말하고, 한 클럭에 걸리는 시간을 클럭 주기(Clock Period 또는 Clock cycle time)이라고 한다. 싱글 사이클 프로세서는 그 사이클 동안 하나의 명령어를 처리하는 프로세서를 의미한다.
Control signal
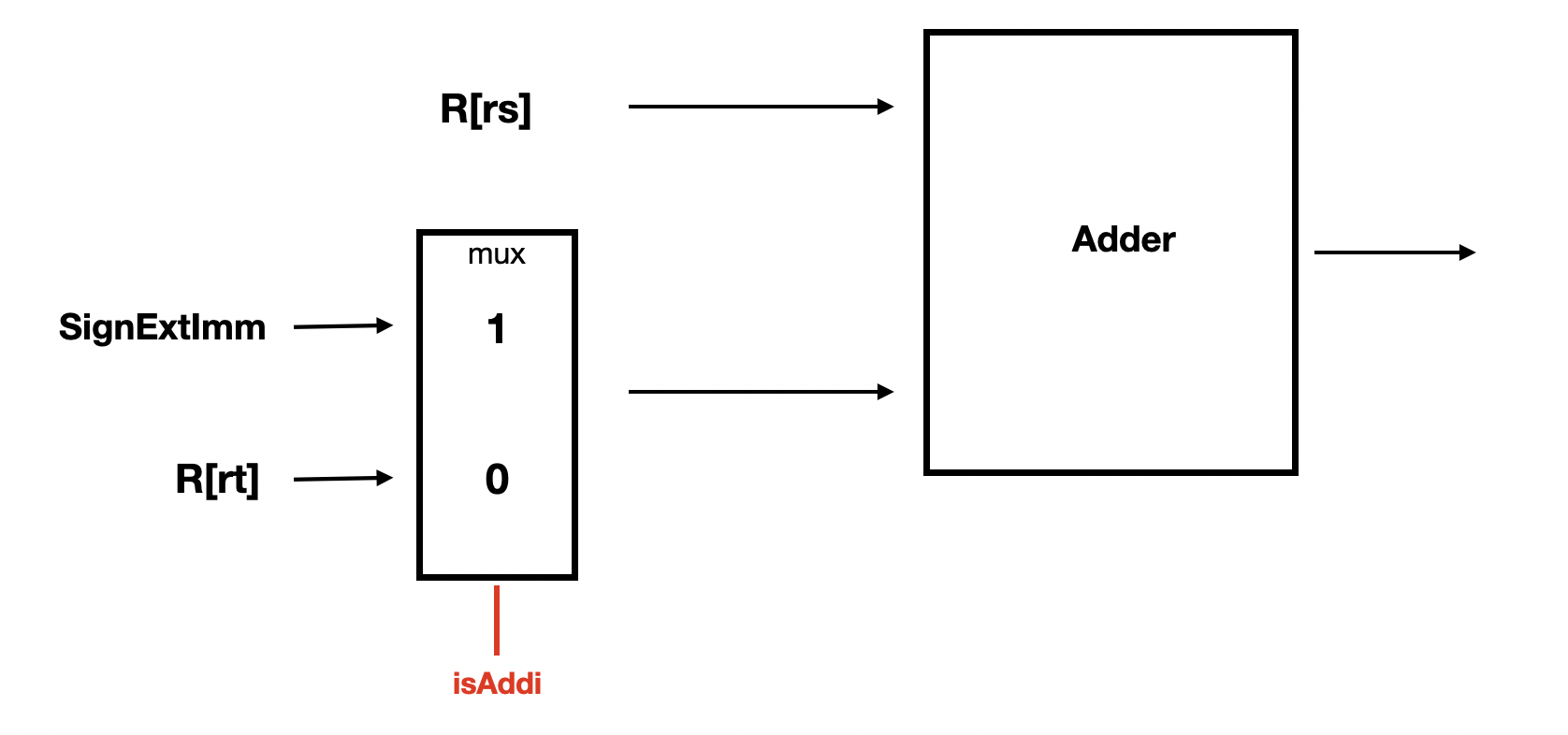
명령어의 종류에 따라 다음 연산의 인자로 들어가는 값을 달리 해야 한다. 이를 테면 Mips에서 Add와 Addi는 ALU 두 인자를 더하는 연산을 처리하는 것은 같지만, 인자로 들어오는 값이 다르다. Add의 경우에는 R[rs]와 R[rt], Addi의 경우에는 R[rs]와 SignExtImm을 인자로 한다.

명령어의 종류(Opcode)에 따라 다른 Control Signal을 만들고, 이 신호를 사용하는 것으로 앞선 경우처럼 인자를 선택하는 등의 다른 여러 선택지에서 적절한 값 또는 연산 종류를 선택할 수 있도록 한다.
아래 그림의 경우처럼 isAddi, 즉 명령어가 Addi인지 여부를 Control Signal 하고, mux에 신호를 주는 것으로 Adder에 R[rs]와 함께 피연산자가 될 값을 선택할 수 있다.
Endian
통상 메모리는 바이트 단위로 접근한다. 그렇다면 8bit를 넘어선 단위의 값은 어떻게 저장할 수 있을까. 더 구체적인 예로 명령어의 크기가 32비트라면 한 명령어를 어떻게 메모리를 쓰고 읽을 수 있을까. 8비트보다 더 큰 값을 메모리에 저장하고자 한다면 이를 나눠 메모리에 담고, 반대로 8비트보다 큰 값을 읽어야 한다면 여러 메모리 주소로 접근하여 값을 더하는 것으로 바이트 단위보다 더 큰 수를 읽는다.
예를 들어, 한 명령어 길이가 32비트인 Mips의 명령어 0x27BDFFF8를 다룬다고 한다면 이를 0x27, 0xBD, 0xFF, 0xF8로 바이트씩 4개로 나눠 메모리에 쓰고 읽을 수 있다. 이때 그 값을 메모리(또는 배열)의 높은 주소부터 접근하는지(읽고 쓰는지), 낮은 주소부터 접근하는지 그 순서에 따라 빅 엔디안, 리틀 엔디안으로 나눌 수 있다. 빅 엔디언은 큰 단위가 앞에 오고, 리틀 엔디언은 작은 단위가 앞에 오게 된다.
이 둘 중 어느 한쪽이 성능적으로 우세하거나, 더 좋은 방식인 것은 아니다. 빅 엔디안은 사람이 숫자를 읽는 방법이랑 같아 메모리 값을 읽기 편하고, 그렇기에 소프트웨어의 디버그에 유리하다는 장점이 있다. 네트워크 데이터 통신처럼 각 바이트를 배열처럼 길게 늘어 쓰는 것이 유리할 때 사용된다. 반대로 리틀 엔디언의 경우 메모리에 저장된 값의 하위 바이트들만 사용할 때 별도의 계산이 필요 없다는 장점이 있기 때문에 물리적으로 데이터를 조작하거나, 산술 연산 시 더 유리하다. Cpu(intel)의 연산이 리틀 엔디언을 사용하는 경우가 많아 대부분의 데스크탑은 리틀 엔디언이 사용된다.

Performance
컴퓨터의 성능은 Cpu가 task를 수행하는 데 걸리는 시간(Cpu time)으로 계산할 수 있다. 앞서 Cpu가 동작하기 위해선 일정 주기의 전기 신호가 필요했고, 이를 Clock cycle으로 소개했다. 그리고 그 한 클럭의 주기(Clock period)가 짧을수록 더 좋은 성능이 좋다고 생각해도 될까. 그렇지 않다. 한 클럭으로 처리할 수 있는 처리량이 다르다. 단순히 서울-부산까지의 왕복 속도로 효율성을 비교하는 것과 같다. 한번 왕복에 처리할 수 있는 승객 수가 다르기 때문에 속도만 빠르다고 좋은 성능의 이동 수단이라고 할 수 없다. 1명으로 10번 왕복하는 것보다 50명을 1번에 왕복하는 것이 더 효율적인 일처리일 테고, 클럭도 마찬가지다. 단순히 Clock period가 작다고, 또는 Clock frenquency가 크다고 더 좋은 성능이라고 할 수 없다. 클럭 주기가 크지만 처리되는 양이 적다면 이는 더 잦은 전기 신호를 사용하고, 더 많은 발열 또는 그 발열을 잡기 위해 크기만 큰 프로세서가 되는 꼴이다.
그렇기에 Cpu Time은 클럭 주기와 프로그램이 처리되기 위한 클럭 수가 결정한다. 이는 프로그램을 처리하는 데 사용되는 클럭 사이클의 수 * 클럭 사이클의 시간으로 계산할 수 있다. Cpu time을 줄이려면 클럭 사이클 수를 줄이거나, 클럭 주기를 줄여야 할 것이다. 프로그램 클럭 사이클 수 = 명령어 수 * 명령어당 평균적으로 사용되는 클럭 사이클 수로 계산할 수 있다. 마찬가지로 명령어 수를 줄이거나, 명령어 당 평균적으로 사용되는 클럭 사이클 수(Cycles Per Instruction)를 줄이는 것으로 Cpu time을 줄일 수 있다.

Classic 5 Stage per instruction
한 명령어가 처리되는 과정을 다음과 같이 5단계로 추상화할 수 있다.
1. Instruction fetch : 메모리에서 PC에 해당하는 명령어를 가져온다.
2. Instruction decode : 명령어를 ISA에 맞게 해석하고, 레지스터에서 적절한 값을 읽는다.
3. Execute : 이전 단계의 해석 값을 인자로 연산한다.
4. Memory : 메모리를 읽거나 값을 쓴다.
5. Write back : 연산 결과를 레지스터에 저장한다.
Multi-Cycle processor
한 클럭에 한 명령어를 실행해야 하는 Single-cycle processor에서는 모든 명령어가 위 5 stage를 거치는 것만큼의 처리 시간을 가져야 한다는 비효율이 있다. 메모리를 참조하고 그 값을 다시 레지스터에 저장하는 Load word는 위 5 단계를 모두 거치고, 그 처리에 걸리는 시간이 곧 클럭 주기가 되어 3단계 만을 필요로 하는 명령어도 LW와 동일한 클럭 주기를 갖게 되는 것이다.
Multi-cycle 방식은 이 처리 stage 별로 클럭을 나눠 명령어를 처리한다. 이것으로 한 클럭 주기는 줄어들고, 3단계까지만 필요한 명령어는 3번의 클럭만, 5단계가 모두 다 필요한 명령어는 5번 클럭이 한 명령어 처리에 필요하게 되는 것이다.
그렇다면 이런 Multi-cycle 방식에선 항상 더 효율적일까? 각 단계를 2ns, 1ns, 2ns, 2ns, 1ns 으로 가정하면, Single cycle에서는 클럭 주기가 8ns(2+1+2+2+1), Multi cycle에서는 2ns이다. 5단계를 모두 처리하는 Load에선 Single-cycle은 8ns, Multi-cycle은 10ns (2*5)가 소요된다. 게다가 Multi cycle에는 그림에는 포함되지 않은 스테이지를 저장하고 불러오기 위한 전환 시간도 존재한다. 이렇게만 봐선 Multi cycle이 더 비효율적인 것처럼 보이지만, 3단계까지만 수행하는 연산의 경우에는 Single cycle은 똑같이 8ns, Multi cycle의 경우는 6ns(2+2+2)으로 Multi cycle이 더 효율적이다.
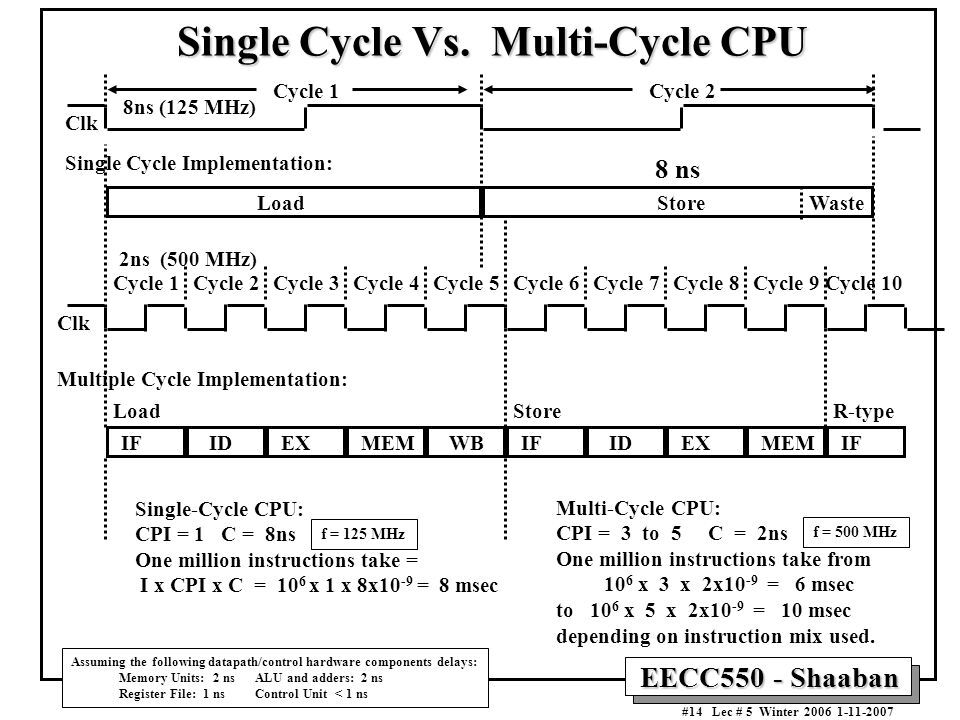
그렇기 때문에 싱글 사이클 프로세서와 멀티 사이클 프로세서 둘을 비교하기 위해선 처리되는 명령어의 종류(분포)를 알아야 할 것이다. CPU 시간은 명령어 수 * CPI * Clock cycle time으로 계산할 수 있고, 이 둘의 비교에선 명령어의 수가 동일하다. 싱글 사이클의 경우 CPI가 1이니 결국 확인해야 하는 것은 싱글 사이클 때의 Clock cycle time과 멀티 사이클의 CPI * Clock cycle time 중 어떤 값이 더 작냐일 것이다.
이때 명령어 처리 stage를 어떻게 나누는 것이 좋을지가 중요한 개선 포인트가 될 수 있다. 특히 한 클럭 사이클에서 처리되는 가장 느린 값(Critical path)이 Clock cycle time을 결정하기 때문에 이 Critical path를 어떻게 분리하는지가 중요하다. 만약 다른 Stage와 Critical path가 되는 Stage의 처리 시간이 너무 차이가 크게 되면 멀티 사이클을 하더라도 Clock cycle time에 개선이 미미하고, CPI만 증가하기 때문에 성능 향상을 기대할 수 없을 것이다. 이럴 때 해당 Stage를 나눠 CPI가 증가함보다 Clock cycle time 감소함이 더 크다면 성능 개선이 가능한 것이다.
예를 들어 5 Stage 중 Memory Access의 처리 시간이 다른 단계들보다 월등히 크다면 이를 Memory Read와 Memory Write의 두 단계로 나누는 것을 고려할 수 있을 것이다. 메모리 읽기와 쓰기를 동시에 하는 명령어가 존재하지 않다면 CPI는 동일, 또는 존재하는 경우에도 그 명령어의 사용이 잦지 않다면 CPI가 살짝 증가함보다, Clock cycle time이 더 크게 감소하기 때문에 이는 합리적인 성능 개선 방법이 될 수 있는 것이다.
State register overhead
그렇지만 Stage를 잘게 세분할수록 성능이 개선되는 것은 또 아니다. 싱글 사이클의 경우에는 한 클럭 안에서 명령어를 읽고 모두 같은 처리를 해주면 그만이지만 멀티 사이클은 한 클럭에서 처리해야 하는 연산이 매번 다르다. 더 구체적으로, 싱글 사이클은 단순하게 1~5단계를 한 클럭으로 처리하면 되지만, 멀티 사이클은 이번 클럭에서 3단계를 처리했으면 이 결과 값과 다음 처리되어야 하는 단계(4)를 Register에 저장해 두고, 다음 클럭에선 이를 읽어 4단계를 처리하게 된다. 이 상태 레지스터를 읽고 쓰는 데에도 시간이 소모된다.
물론 앞선 예시들의 경우처럼 5단계로 나눴을 때와 비교하면 무의미해 보일 수 있으나, 이 단계를 더 세분화하여 나눈다면 결국 Clock cycle time의 감소보다 이 상태 레지스터 사용으로 인한 overhead가 더 커질 것이다. 이런 이유로 Stage를 무한히 나눠 성능을 개선할 수는 없는 것이다.
Amdahl's Law
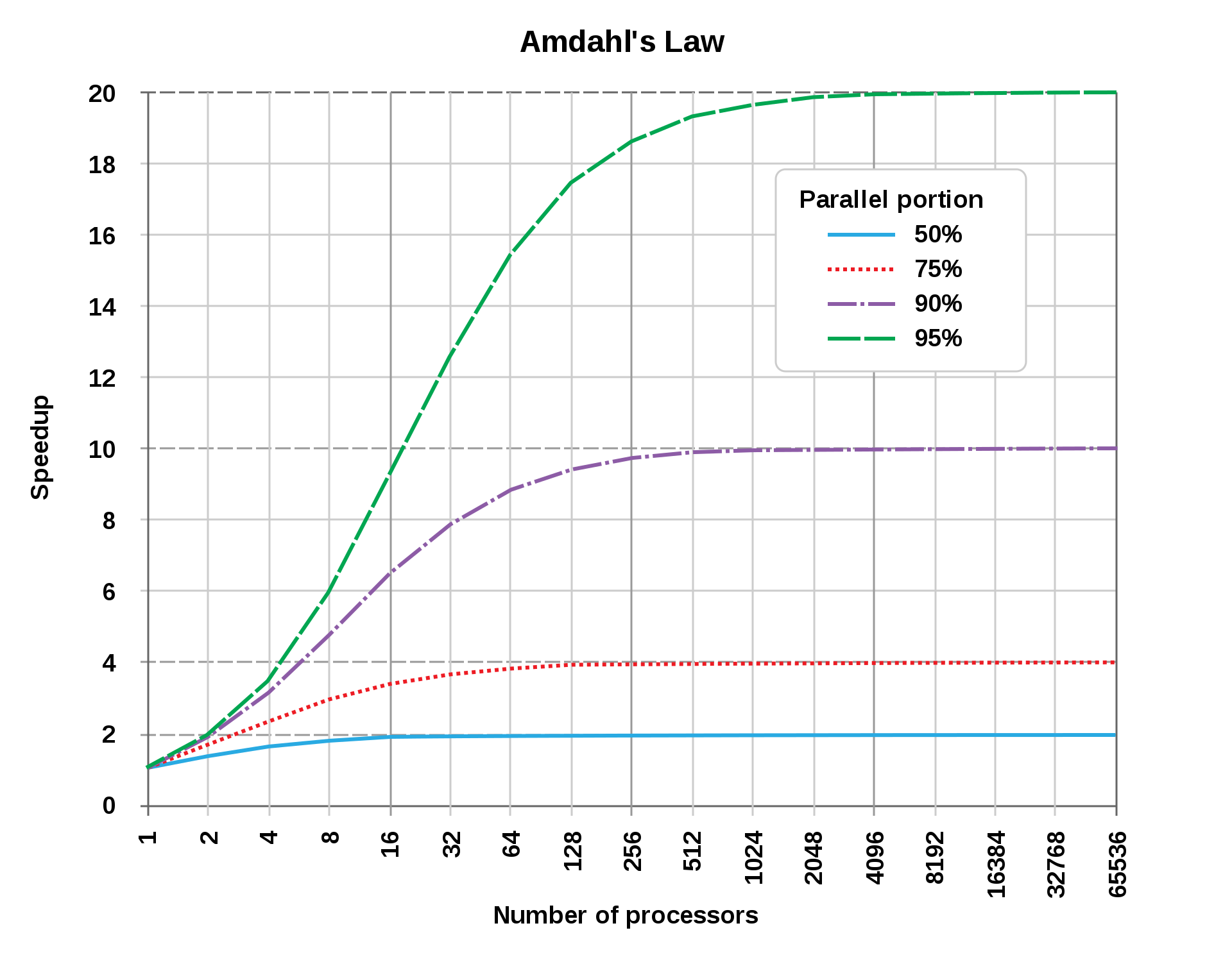
Amdahl의 법칙은 컴퓨팅 시스템 일부 성능 개선이 곧 전체 성능 개선으로 이어지지 않는 것을 말한다. 해당 시스템이 영향을 받는 분과 받지 않는 부분을 고려해야 하고, 성능 최적화를 하더라도 일정 수준 이상의 성능 최적화에는 분명한 한계가 있음을 말한다.
예를 들면 순차적으로 처리해야 하는 작업(20%)과 병렬 처리가 가능한 작업(80%)이 있는 시스템이 있다고 가정해보자. 해당 시스템의 프로세스를 늘려 병렬 처리를 처리하면, 프로세스 수에 따라 성능이 향상될 것 같지만 사실 그렇지 않다. 초반의 프로세스 수에는 큰 영향을 받아 80%를 차지하는 병렬 처리가 훨씬 더 빠른 성능 개선의 포인트를 보일 테지만, 그 수가 늘어날수록 결국 순차적으로는 처리해야 하는 작업을 기다리기 위해 개선의 정도가 점점 감소하고, 한계에 도달하게 된다. 그 경우에는 프로세스를 늘리는 것이 아닌, 직렬 작업 (20%)를 조금 더 빠르게 개선하는 것만으로도 큰 성능 개선이 가능한 것이다.
즉 Amdahl's Law는 성능 개선의 한계와 전체 시스템에서 차지하는 영향 계산의 중요성을 말한다. 프로세스 설계자들은 자신이 개선하고 싶은 부분이 전체에서 어느 정도의 영향을 차지하는지 계산하고 그 우선순위를 정해야 한다.
'Computer Science > Computer architechture' 카테고리의 다른 글
| 싱글사이클 기반 MIPS 프로세서 설계 (0) | 2022.04.24 |
|---|---|
| 캐시의 개념과 종류 / 쓰기 정책과 교체 정책 (0) | 2019.07.05 |
| 명령어 파이프라이닝 / Forwarding과 분기 예측 (0) | 2019.07.01 |
| 컴퓨터 추상화 / 퍼포먼스 (0) | 2019.06.24 |
| Buffer / Cache (0) | 2019.01.09 |