

ecsimsw
천만 개 데이터로 조회 성능 확인, 인덱스와 쿼리 튜닝 본문
소개
DB에 데이터가 쌓였을 때 조회 성능과 개선 포인트를 확인했다. DB 쿼리 빈도를 줄여 조회 성능을 개선하는 캐싱이나 DB 부하 분산은 다루지 않는다. 대신 데이터를 만드는 방법부터 DB 엔진에 넣는 데 걸리는 시간, 인덱스나 쿼리 수정 고민 과정을 적어볼 생각이다. 튜닝 키워드는 아래와 같다.
1. 더미 데이터를 추가하고 쿼리 조회 성능을 확인한다.
2. 인덱스/커버링 인덱스를 적용한다.
3. 실행 계획으로 인덱스 튜닝 결과를 확인한다.
4. OFFSET 기반 페이지네이션의 문제를 확인하고 개선한다.
천만 개 더미데이터 삽입
테스트 환경으로 1000명 유저, 각 유저는 20개의 앨범을 소유, 각 앨범에는 500개의 사진 정보를 가정한다. 총 천개의 Member 데이터, 2만 개의 Album 데이터, 천만 개의 Picture 데이터를 삽입했다.
Application 내에서 데이터 삽입시 예상 시간이 1시간이 넘었고, DB에 직접 데이터를 넣는 방식으로 업로드 시간을 줄였다. 프로시저로 300개씩 Bulk insert 와 File insert 에 시간 차이는 크지 않았지만, CSV 파일을 만드는 코드를 짜는 것이 FK, Row 수 등 세부 설정과 코드 관리에 유리하다고 판단했다. 1시간 반을 예상했던 더미데이터 업로드가 3분 13초로 단축할 수 있었다.

유저의 앨범 목록 조회, 인덱스
유저 ID 697의 앨범 리스트를 조회하는 쿼리는 다음과 같다. 24 ms 의 execution time 이 발생한다.
Fetch time 은 값을 불러오는데 필요한 시간이라 쿼리 튜닝에서 확인할 대상이 아니다.
SELECT * FROM ALBUM WHERE USERID = 697
9 rows retrieved starting from 1 in 40 ms (execution: 24 ms, fetching: 16 ms)
실행 계획을 확인해보면 rows = 20172, filtered = 10.0, extra = using where 인 것을 확인할 수 있다. 스토리지 엔진에서 20172 개 로우의 데이터를 접근하고, Mysql 엔진에서 where 조건에 필터링되어 10% 만 남을 것을 예상한다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | ALBUM | NULL | ALL | NULL | NULL | NULL | NULL | 20172 | 10.00 | Using where |
조건절에 사용되는 컬럼 (USERID) 에 인덱스를 추가한다. 접근 로우 수가 9개로 줄어들고 type 이 ref 로 바뀐 것을 볼 수 있다.
type는 데이터를 어떻게 찾을지를 표시한다.
const : 인덱스 단건, all : 풀스캔, index : 인덱스 풀스캔, ref : 인덱스 등가 비교, range : 인덱스 범위
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | ALBUM | NULL | ref | ALBUM_USERID | ALBUM_USERID | 9 | const | 9 | 100.00 | NULL |
유저 사진 조회, 멀티 컬럼 인덱스
유저 사진을 조회 쿼리를 확인한다. 먼저 튜닝 전 쿼리와 시간은 다음과 같다.
SELECT P.ID FROM PICTURE AS P JOIN ALBUM AS A ON P.ALBUMID = A.ID
WHERE A.USERID=697
ORDER BY A.TITLE, P.ID
LIMIT 10 OFFSET 20
10 rows retrieved starting from 1 in 19 s 860 ms (execution: 19 s 780 ms, fetching: 80 ms)
실행 계획을 살펴보면 Picture 테이블에서 검색, 정렬이 일어나고 있고 모든 로우를 다 읽고 있다.
조인, 검색으로 사용되는 컬럼에 인덱스를 추가하여 읽어 들이는 로우 수를 줄여본다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | P | NULL | ALL | NULL | NULL | NULL | NULL | 9714204 | 100.00 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | A | NULL | eq_ref | ALBUM_PK,ALBUM_USERID_TITLE | ALBUM_PK | 9 | dbtest.P.ALBUMID | 1 | 5.00 | Using where |
Picture의 {ALBUMID, ID} 에, Album 에는 {USERID, TITLE, ID} 으로 인덱스를 추가한다.
Picture 에서 읽는 row 수가 527 로 크게 줄은 것을 볼 수 있다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | A | NULL | ref | ALBUM_PK,ALBUM_USERID_TITLE,ALBUM_USERID_TITLE_ID | ALBUM_USERID_TITLE_ID | 9 | const | 9 | 100.00 | Using where; Using index |
| 1 | SIMPLE | P | NULL | ref | PICTURE_ALBUM_ID | PICTURE_ALBUM_ID | 9 | dbtest.A.ID | 527 | 100.00 | Using index |
이렇게 여러 컬럼을 키로 한 인덱스를 생성하는 방법을 멀티 컬럼 인덱스라고 한다. 멀티 컬럼 인덱스에서 { A, B } 로 인덱스를 추가하는 것과 { B, A } 로 인덱스를 추가하는 것은 다르다. 멀티 컬럼 순서에 따라 인덱스 정렬이 결정되고, 검색과 정렬에 활용될 수 있는 여부가 달라진다.
예시에선 조인, 조건 검색, 정렬 순서로 인덱스가 사용되었다.
SELECT P.ID FROM PICTURE AS P JOIN ALBUM AS A ON P.ALBUMID = A.ID
WHERE A.USERID=697
ORDER BY A.TITLE
LIMIT 10 OFFSET 20
10 rows retrieved starting from 1 in 44 ms (execution: 12 ms, fetching: 32 ms)
쿼리 실행 시간은 12ms 가 나온다. 처음 19.780sec 에서 크게 개선된 수치이다.
유저의 앨범 목록 제목 조회, 커버링 인덱스
이번엔 유저의 앨범 목록을 조회하면서 앨범 제목만을 가져오려고 한다. 만약 조회하고자 하는 컬럼이 모두 모두 인덱스로 등록되어 있다면, 데이터 노드에 접근하지 않고도 인덱스만으로 조회를 마칠 수 있다. 이렇게 인덱스에 조회에 필요한 컬럼들이 모두 등록되어 있어, 인덱스 조회만으로 쿼리가 수행될 수 있는 경우를 커버링 인덱스라고 한다.
아래 쿼리에서 검색을 위한 인덱스 { USERID }에 { TITLE } 을 함께 추가한 { USERID, TITLE } 을 인덱스로 생성하여, 커버링 인덱스를 만든다.
SELECT TITLE FROM ALBUM WHERE USERID = 697
9 rows retrieved starting from 1 in 26 ms (execution: 5 ms, fetching: 21 ms)
실행 계획의 Extra 에 'Using index' 로 커버링 인덱스가 적용되었음을 확인할 수 있다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | ALBUM | NULL | ref | ALBUM_USERID,ALBUM_USERID_TITLE | ALBUM_USERID_TITLE | 9 | const | 9 | 100.00 | Using index |
전체 유저 사진 페이지네이션 조회, 커서 기반 페이지네이션
페이지가 큰 경우에서 페이지네이션 조회 쿼리의 성능을 확인한다. OFFSET 방식의 페이지네이션에서 위는 페이지 번호가 낮은 경우의 쿼리, 아래는 페이지 번호가 큰 경우의 조회 결과이다. 페이지가 작은 경우에는 31 ms 로 괜찮지만, 페이지가 큰 경우에는 5분도 넘게 걸려 튜닝이 필요하다.
SELECT P.ID FROM PICTURE AS P JOIN ALBUM AS A ON P.ALBUMID = A.ID
ORDER BY A.TITLE, P.ID
LIMIT 10 OFFSET 20
10 rows retrieved starting from 1 in 57 ms (execution: 31 ms, fetching: 26 ms)SELECT A.TITLE, P.ID, P.DESCRIPTION FROM PICTURE AS P JOIN ALBUM AS A ON P.ALBUMID = A.ID
ORDER BY A.TITLE, P.ID
LIMIT 10 OFFSET 9000000
10 rows retrieved starting from 1 in 5 m 36 s 581 ms (execution: 5 m 36 s 493 ms, fetching: 88 ms)
이렇게까지 큰 차이를 보이는 이유는 OFFSET 동작 방식 때문이다. Mysql 의 OFFSET 은 그저 페이지까지의 전부를 읽고 필요한 부분의 이전 데이터는 버리는 식으로 동작한다. 페이지가 커지면 커질 수록 조회해야 하는 데이터는 점점 많아지고 느린 응답을 받게 되는 것이다.
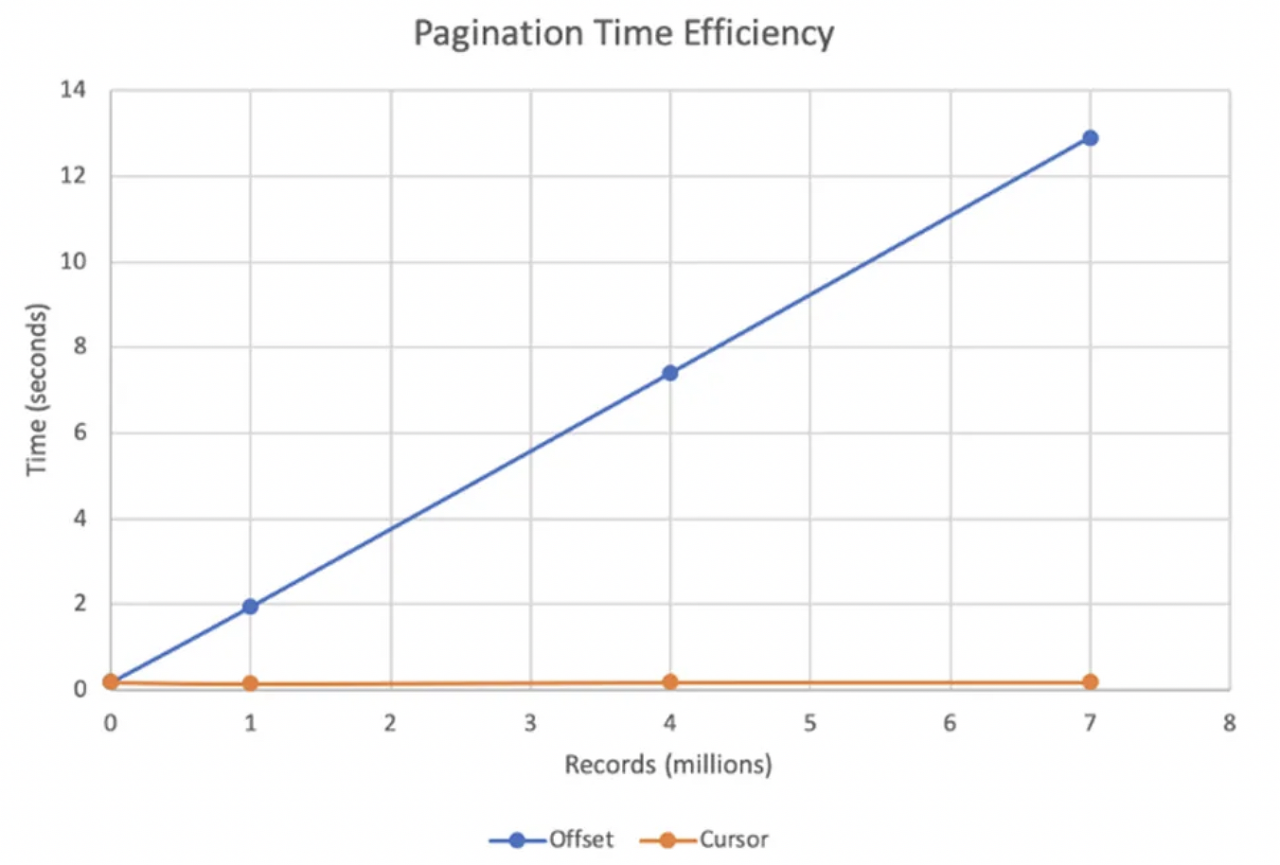
커서 기반의 페이지네이션으로 페이지네이션 방식을 바꿔 페이지가 커지더라도 매번 동일한 조회 속도를 가질 수 있도록 개선한다. '명확한 정렬 방법이 있고, 조회할 페이지는 이전 페이지 마지막 아이템의 다음 N개' 라면 커서 기반 페이지네이션을 사용할 수 있다. 정렬의 기준이 되는 컬럼에 인덱스가 적용하여 조회 성능을 높인다.
아래는 커서 기반 페이지네이션을 적용한 조회 쿼리와 그 결과이다.
SELECT A.TITLE, P.ID, P.DESCRIPTION FROM PICTURE AS P JOIN ALBUM AS A ON P.ALBUMID = A.ID
WHERE A.TITLE >= 'WvdVj7GbU' AND P.ID >= 4120335
ORDER BY A.TITLE, P.ID LIMIT 10
10 rows retrieved starting from 1 in 44 ms (execution: 11 ms, fetching: 33 ms)
앞선 OFFSET 기반과 달리 단순 조건 처리이기에, 5분 36초가 걸리던 쿼리가 11ms 로 개선된 것을 확인할 수 있다.
그 밖의 DB 조회 성능 개선 포인트
이번 실습으로 DB에 1000만개의 데이터를 넣는 방법도 고민해 보고, 그 데이터를 바탕으로 프로젝트 주요 쿼리의 조회 성능을 확인해 보았다. 그리곤 인덱스, 커버링 인덱스를 적용하고 실행 계획 확인으로 인덱스가 의도대로 적용되었는지 확인했고, OFFSET의 동작 방식의 문제를 쿼리로 튜닝할 수 있었다.
Picup 에서 DB 성능을 위해 고민했던 키워드를 정리하고 글을 마무리하려고 한다. 실습 재밌었다.
1. 비효율적인 쿼리 자체를 개선
: 쿼리 자체가 비효율적인 경우는 없는지 확인한다. 예를 들어 페이지네이션 방식을 변경했고, 인덱스 기반 페이지네이션에선 필요했던 전체 row 수 조회 쿼리가 불필요해졌다.
2. 인덱스 사용
: DB 인덱스를 추가하여 조회 성능을 개선했다. 실행 계획으로 인덱스가 의도한대로 사용되는지 확인했고, 커버링 인덱스를 적극적으로 활용했다.
3. 캐시로 DB 액세스 횟수 개선
: 자주 사용되는 데이터를 캐싱하여 DB 접근 횟수를 줄였다. 분산 환경에서 WAS 간 캐시 데이터 공유를 위해 Redis 를 사용했다.
4. 레플리케이션, 샤딩으로 DB 부하 분산
: DB 를 복제하여 Transaction 종류에 따라 라우팅할 DB 를 나눠 부하를 분산했다.
5. 역정규화로 Join 쿼리 개선
: 정규화로 반드시 사용되는 쿼리에 불필요한 Join 문이 매번 발생했다. 역 정규화를 통해 조인없이 한 테이블 안에서 직접 처리할 수 있도록 하였다.
6. DB 락 범위 축소
: DB 락의 락 범위를 확인하고 Table based lock -> Row based lock 으로 범위를 줄여 대기 빈도와 충돌 횟수를 개선했다.