
ecsimsw
대기열 사이즈와 OOM 문제 해결 본문
OOM 발생
회사 기기 수가 급격하게 늘고 있다. 100만대를 축하한게 불과 3,4개월 전이었던거 같은데 벌써 200만대를 넘었다.
기기 수가 늘어남에 따라 기기 이벤트 수가 급증했고, 기기 이벤트를 수신하여 후처리 하는 서버에서 OOM이 발생하는 문제가 생겼다. 특정 시간대에서 스파이크성 트래픽이 발생하는 것은 아니고, 서버를 실행하고 N시간 후에 OOM과 함께 서버가 다운된다.
이 글에선 해당 문제를 모니터링했던 방법과 원인, 해결 방안을 정리한다.
원인 파악
메모리 누수 파악
서버의 힙 메모리와 GC 동작 기록이다. 위 보드의 노란색이 Old Gen, 아래 보드의 파란색과 녹색이 각각 Minor GC, Major GC이다. GC 동작 이후에도 Old Gen의 최저 수위가 점점 높아지는 것을 볼 수 있다. Major GC의 처리 대상이 되지 못하는 누수가 계속 쌓이고 있고, 결국 Old gen이 메모리를 가득 채워 OOM이 발생하게 된다.
OOM에 메모리 누수를 예상했지만서도, 다른 변경이 전혀 없이 그간 한 번도 문제를 일으키지 않았던 서버라 의아했다.

Heap dump
'-XX:+HeapDumpOnOutOfMemoryError'를 사용하면, 서버가 OOM으로 죽는 시점에서 Heap dump 파일을 남길 수 있다. LinkedBlockingQueue가 90% 이상의 메모리를 사용하고 있는 것을 확인했고, 코드에서 사용처를 쫓기 시작했다.
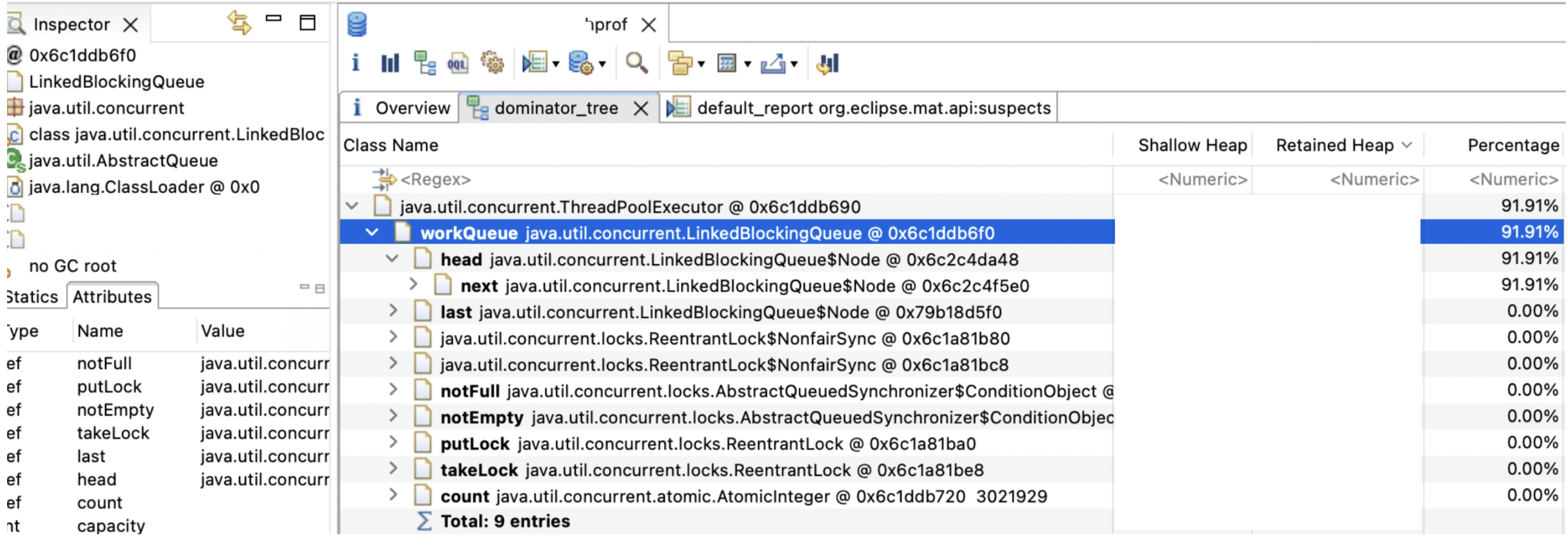
코드 분석
ExecutorService
해당 서버는 처리 로직 안에서 비동기 처리를 위해 ExecutorService를 사용하고 있다. ExecutorService의 ThreadPoolExecutor는 기본값으로 LinkedBlockingQueue를 사용하고 있고, 스레드가 부족한 상황에서 들어오는 작업을 이 큐에 저장하여, 후에 FIFO로 처리되게 된다.
다른 Capacity를 지정이 없다면, 이 대기열은 Integer.MAX_VALUE를 크기 제한으로 갖게 된다. GC는 이 대기열을 수집 대상으로 보지 않기 때문에, 너무 많은 작업이 이 대기열에 쌓이게 되면 모든 Heap을 차지하며 OOM을 발생할 수 있는 원인이 될 수 있다.
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(
nThreads,
nThreads,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()
);
}
처리량과 유입량
ExecutorService로 들어오는 비동기 작업에 대한 처리량이 유입량보다 컸던 것이 문제의 원인이었다. 해당 서버는 기기 이벤트를 수신하여 후처리 하는 서비스였는데, 회사의 활성화 기기가 점점 늘어나면서 기존에는 처리량 > 유입량이었던 것이, 지금은 처리량 < 유입량이 되었던 것이다. 처리량을 따라가지 못한 유입 이벤트는 크기가 제한되지 않았던 대기열(LinkedBlockingQueue)에 쌓였고, GC에 수집되지 못한 채 조금씩 늘어나 결국 모든 Heap 메모리 영역을 차지하게 된 것이다.

해결 방안
처리량 늘리기 - Thread 수 늘리기, 캐시 처리
처리량을 유입량보다 늘려 대기열에 작업이 쌓이지 않도록 한다. 스레드 수를 늘리고 병목 포인트를 확인했다. 로직 안에 DB 조회가 있어, 커넥션 점유에 병목이 발생하지 않도록 DB CP 수도 늘렸다. 캐시를 사용하여 DB 쿼리 없이 빠르게 조회할 수 있도록 했다.
유입량 줄이기 - 이벤트 필터링
반대로 처리량보다 유입량을 줄여 대기열에 작업이 쌓이지 않도록 한다. 수신한 이벤트 중 처리가 필요한 이벤트 필터링 점검했다. 시간이 오래되어 처리가 불필요하다고 생각되는 이벤트는 애초에 비동기 작업을 수행하지 않고 유실시킨다.
메모리 사용 제한 - 대기열 사이즈 설정
위 방안으로 처리량을 높이고 유입량을 줄였지만, 기기 수가 늘고 이벤트 수가 늘면 언젠가는 다시 처리량보다 유입량이 커지는 상황이 발생할 것이다. 대기열 사이즈(Capacity)를 조정하여 대기 작업 수를 제한한다. OOM 발생이라는 최악의 상황을 막을 수 있다.
'KimJinHwan > Project' 카테고리의 다른 글
| 팀에서 테라폼을 도입하고 얻은 것들 (0) | 2025.01.01 |
|---|---|
| 이벤트 전달 유실 개선, SNS+SQS를 선택한 이유 (2) | 2024.12.29 |
| S3 업로드 속도 개선, Pre-signed url과 Thumbnail Lambda (0) | 2024.05.31 |
| 현재 사용 불가능한 API의 응답을 자동 생성해주는 라이브러리 (0) | 2024.01.17 |
| JNI 임베디드 프로그래밍 (0) | 2022.06.19 |