
ecsimsw
RepeatableRead 에서 발생할 수 있는 동시성 문제와 락 본문
Mysql InnoDB 의 RepeatableRead
Mysql 의 기본 Transaction isolate 수준은 RepeatableRead 이다. RepeatableRead 는 트랜잭션이 시작된 시점 이후로 여러 번 Select Row 를 확인해도 동일한 값을 갖는다는 것이다. Mysql 은 SnapShot을 사용해서 이를 보장한다. 트랜잭션마다 별도의 스냅샷을 기록하여 다른 트랜잭션이 값을 변경하고 Commit 해도 이 스냅샷을 이용해서 동일한 값을 읽게 되는 것이다.
Phantom read 문제
Repeatable Read 는 데이터의 추가, 삭제의 변경은 막지 못해 Phantom read 문제가 발생한다. 한 트랜잭션 내에서 전과 다른 조회 결과 row 수를 조회하게 된다는 것이다.
InnoDB의 Repeatable Read 에선 Phantom read 가 발생하지 않는다. InnoDB는 record 와 record 사이를 lock 하는 Gap lock 을 사용하는 것으로 데이터 추가, 삭제에도 전과 동일한 값을 조회할 수 있도록 한다. 정확하게는 Record lock 과 Gap lock 을 함께 사용하는 Next key lock 를 사용해서 트랜잭션 내에서 동일한 row 수와 값 조회를 보장한다.
Exclusive lock 과 Shared lock / Dead lock 문제
Exclusive lock 은 다른 트랜잭션의 Exclusive lock / Shared lock 의, Shared lock 은 다른 트랜잭션의 Exclusive lock 을 자원 점유를 막는다.
Mysql 의 Repeatable Read 에선 SELECT는 Lock 없이 조회하고, UPDATE 는 Exclusive lock 이 Row 별로 걸리게 된다. 이때 쿼리 인덱스 사용에 따라 테이블 락이 걸릴 수 도 있다. 또 FK 가 있는 CUD 쿼리에서 Shared lock 이 발생할 수 있다고 한다. "SELECT ~ FOR UPDATE", "SELECT ~ FOR SHARE" 으로 쿼리에 Exclusive lock, Shared lock 를 사용하는 것으로 조회 시에도 락을 강제할 수 있다.
예를 들면 A 트랜잭션에서 자원1에 UPDATE 를 수행하면 A 트랜잭션에선 자원 1에 배타 락을 걸게 되고, B 트랜잭션에 해당 자원에 UPDATE 를 수행하고자 하더라도 배타 락을 걸 수 없어 트랜잭션A의 완료를 대기하게 된다. 이때 배타 락이 걸려있지 않더라도 락을 필요로 하지 않는 SELECT 요청은 자원 1에 접근할 수 있다.
이렇게 자원을 점유하게 될 때는 데드락을 주의해야 한다. 데드락은 자원을 서로 엇갈라 가지고 있어 그 누구도 처리를 마치고 자원을 반납할 수 없게 되는 상황을 말한다. 예를 들어 A 가 1을 점유하고 있는 상황에서 2가 필요하고, B 가 2를 갖고 있는 상황에서 3가 필요하고 , C가 3을 갖고 있는 상황에서 다시 1을 필요로 한다면 이 셋은 그 누구도 처리를 마치지 못하고 각자의 자원을 점유한 채 끝없이 기다리는 상황에 놓이게 될 것이다.
이런 데드락을 피하기 위해 트랜잭션에서 점유할 자원의 순서와 락 방식을 고려해야 하고, 데드락이 생겼을 때는 욕심쟁이 트랜잭션들이 자원을 포기하여 다시 처리가 진행되게끔 락의 타임 아웃을 줘야할 것이다.
기본 격리 수준과 락 전략에서 생길 수 있는 동시성 문제
동시성 문제는 공유하는 한 자원에 여러 작업이 동시에 처리되면서 의도한 것과 다른 동작으로 이어지는 문제 상황을 말한다. 여러 요청이 동시에 처리되어 스레드마다 서로 다른 트랜잭션을 갖을 때 앞선 기본 격리 수준과 락 전략으로만 데이터를 다룬다면 의도하지 않은 상황을 만날 수 있다.
@Transactional
public void addUsage(Long userId=1, Long fileSize=10) {
var usage = query.execute("select * from storage_usage where user_id =1");
if (usage.limit < usage.used + fileSize) {
throw new IllegalArgumentException("유저 스토리지 가능 용량을 넘어버린 파일 업로드");
}
usage.used += fileSize;
query.execute("update storage_usage set usage_as_byte=${usage.used} where user_id=1");
}
위 메서드는 Picup 프로젝트에서 사용자 사진이 업로드 되었을 때 스토리지 사용 공간을 업데이트하는 로직이다. 조회 후 업로드 하는 파일 사이즈가 제한 공간을 넘어서는지 확인하고 불가능하면 예외를 발생시킨다.
만약 동시에 두 스레드에서 addUsage 가 호출되면 어떻게 될까. 현재 사용량이 0, 제한이 15이고 사진 파일 크기가 10이라고 가정하고 DB 처리 흐름을 따라가 보자.
조회에서 락이 걸리지 않으니 두 스레드 DB에서 제한이 0이고 현재 사용량이 0 임을 조회할 것이고, 먼저 update 에 도착한 A 트랜잭션이 user_id =1 인 row에 배타락을 걸어 유저의 현재 사용량을 10으로 업데이트하고 커밋할 것이다. 커밋을 마치기 전까지 B 트랜잭션은 업데이트를 수행하지 못하다가 A 가 커밋되면 다시 유저의 현재 사용량을 10으로 업데이트하고 커밋하게 된다.
둘 중 하나는 실패했어야 할 2개의 요청이 모두 정상 처리되고 유저의 현재 사용량은 20이 아니라 10으로 기록되는 의도와 다른 상황을 맞게 되는 것이다.
동시성 문제 해결 - Synchronized
synchronized 를 사용해서 애플리케이션 수준에서 애초에 addUsage가 여러 스레드에서 동시에 호출되는 것을 막고 순차적으로 처리되게 강제하면 '조회 후 수정 -> 조회 후 수정'이 보장되니 동시성 문제가 해결되겠다.
@Transactional
public synchronized void addUsage(Long userId, long fileSize) {
}
다만 userId와 상관없이 addUsage 메서드 자체가 동시 처리가 안되기 때문에 유저 1과 유저 2의 서로 다른 row 에서도 불필요하게 트랜잭션 간 격리가 이뤄져 요청 주기가 길어지게 될 것이고, 무엇보다 애플리케이션 단에서의 처리 이기 때문에 여러 WAS 를 사용하는 분산 환경에서는 불가능한 옵션이 될 것이다.
동시성 문제 해결 - 비관적 락
DB 수준에서 읽기에 락을 지정하는 것으로 업데이트 이후에 조회를 보장하는 것으로 동시성 문제를 해결할 수 있다. 업데이트에는 기본적으로 배타락이 걸리기 때문에 조회에 락을 걸어 업데이트 이후 조회를 보장하게 된다.
JPA에선 이를 @Lock 어노테이션을 사용하여 처리할 수 있다. LockModeType 의 PESSIMISTIC_WRITE 으로 x-lock 을, PESSIMISTIC_READ 으로 s-lock 을 조회 쿼리에 사용할 수 있다. 업데이트로 배타락을 잡고 있던 트랜잭션이 Commit 되면 그제야 읽기 쿼리가 수행된다.
public interface StorageUsageRepository extends JpaRepository<StorageUsage, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
Optional<StorageUsage> findByUserId(Long userId);
}
Mysql의 격리 수준 중 Serializable 은 기본 격리 수준인 RepeatableRead 에 더해 읽기 시 s-lock 을 사용한다. 이를 이용하면 쿼리에 직접 Lock 을 설정하는 것이 아니라 격리 수준을 높여 해당 트랜잭션에서 발생하는 읽기에 락을 추가할 수 있다.
@Transactional(isolation = Isolation.SERIALIZABLE)
public void addUsage(Long userId, long fileSize) {
}
메서드에 직접 락을 지정하는 것과 트랜잭션 격리 수준을 올리는 것 둘 중 어떤 방법이 더 좋냐는 없을 것 같다. 조회 시 락을 사용하지 않는 경우가 많고 특정 로직에서 딱 한번 락이 필요하여 또 다른 조회 메서드를 정의해야 하거나 아예 모든 조회에 락을 줘야 하는 경우라면 그냥 그 로직에만 격리 수준을 Serializable 으로 할 수 있을 것도 같고, 지금 예시의 사용량처럼 row 별 격리가 워낙 중요하거나 조회에 락을 걸어야 하는 쿼리와 아닌 조회 쿼리가 혼합되어 있는 경우라면 그냥 해당 메서드에 Lock 을 직접 추가하는 게 더 나을 것 같다.
더 큰 문제는 Dead lock 과 조회 성능이다.
Dead Lock 과 조회 성능
위 예시에서 조회 시 Shared lock 을 사용해서 조회 후 업데이트 하였다고 가정해 보자. 사용자의 스토리지 사용량을 조회하고 업데이트하는 트랜잭션은 아래처럼 동작할 것이다.
start transaction;
select * from storage_usage where user_id =1 for share;
update storage_usage set usage_as_byte=20 where user_id=1;
commit;
이때 2개의 요청이 동시에 들어온다고 가정해보자. A, B 트랜잭션이 자원 1에 공유 락을 걸게 된다. 공유 락은 공유 락끼리 잠금이 없기 때문에 여러 공유락에 의해 한 자원을 점유하고 있는 것이 가능하다.
문제는 다음 UPDATE 의 처리를 고민해 보자. A 트랜잭션은 B 트랜잭션의 공유 락 때문에 업데이트를 위한 배타 락을 얻지 못하고 B 트랜잭션이 종료되기만을 기다린다. 그리고 이후 B 트랜잭션이 똑같이 업데이트를 위한 배타 락을 얻지 못하고 A 트랜잭션이 종료되기만을 기다린다. A, B 모두 상대가 종료되어야만 본인이 종료될 수 있는 상황이므로 데드락이 발생한다.
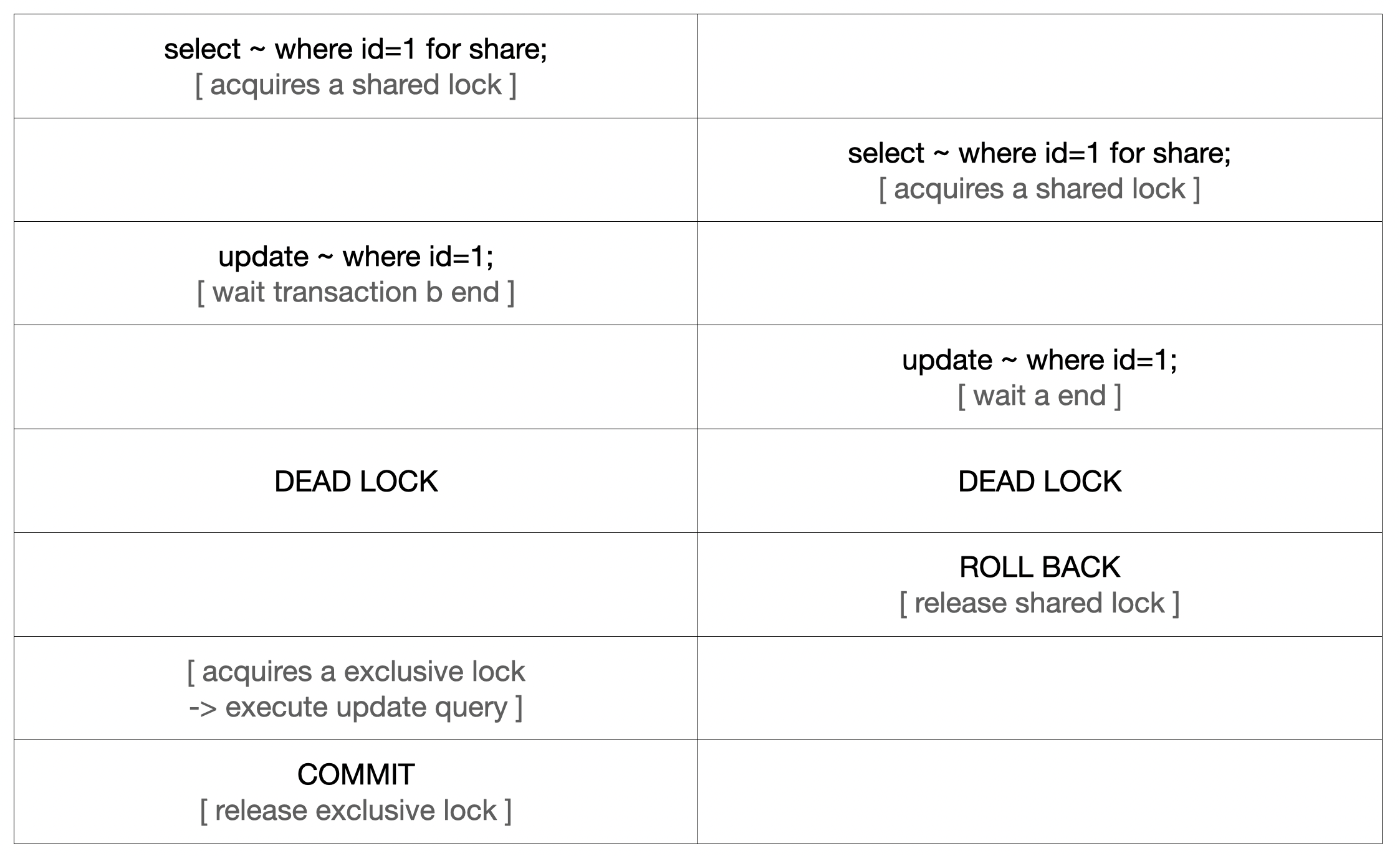
Mysql 의 기본 설정에선 데드락이 감지되면 데드락 조건을 확인하고 관련 중 일부 트랜잭션을 희생시킨다. 그 덕에 위 도표에서 데드락 발생 후 B가 희생되어 A는 배타락을 얻어 Update 를 결국 수행하게 된다.
이런 데드락 문제는 트랜잭션 주기를 최대한 짧게 가져하거나 조회 락과 점유 자원을 고려하는 것으로 해결할 수 있다. 예를 들어 위 예시에서 조회 시 사용하는 Lock 이 배타 락이면 데드락 문제가 발생하지 않는다. A의 트랜잭션이 종료되면 그제야 B 트랜잭션의 조회가 처리되기 때문이다. 그렇기에 한 자원에 락이 몰리게 되면 연쇄적인 처리가 필요하므로 DB 처리가 늦어지는 문제가 발생한다.
락의 범위 확인하기
처리 로직에서 사용자 사용 공간을 조회하는 쿼리에 배타 락을 걸면 여러 요청이 들어와도 트랜잭션끼리 분리가 되기에 동시성 문제를 해결할 수 있다. 발생할 수 있는 문제로 조회 성능을 얘기했는데, 조회에 사용되는 락의 범위가 Row 별인지, Table 별인지가 조회 성능을 크게 좌우한다.
만약 조회에 데이터가 사용자 별로 다른 Row 를 갖고, 조회에 거는 락이 Row 락이 사용된다면 동일 사용자 요청 외에는 락에 영향을 받지 않을 것이다. 요청이 몰리게 되더라도 다른 사용자의 조회와는 상관없이 조회 성능이 나올 것이고, 한 사람이 여러 요청을 동시에 많이 보낸 경우에만 문제가 된다.
## Case 1 - PK 가 ID이고 UserId를 조회하는 상황
start transaction;
select * from storage_usage where user_id=1 for update;
update storage_usage set limit_as_byte=100, usage_as_byte=28 where id=1;
commit;
## Case 2 - PK 가 UserId이고 UserId를 조회하는 상황
start transaction;
select * from storage_usage where user_id=1 for update;
update storage_usage set limit_as_byte=100, usage_as_byte=28 where user_id=1;
commit;
위는 PK 가 Id 인 상황에서 UserId로 사용자 공간을 조회하여 업데이트하는 것, 아래는 PK가 UserId 인 상황에서 사용자 공간을 업데이트 하는 상황이다. 이 둘이 별 차이가 없어 보여도 조회 사용된 Lock이 Case 1에서는 Table 락으로, Case 2에서는 Row 락으로 처리된다.
만약 case 1 과 같은 상황이라면 비관적 락이 매우 비효율 적이겠다. 여러 사용자의 업로드에서 업로드하는 당사자의 row에 동시성 문제가 아닌 전혀 관련 없는 다른 사용자의 업로드를 매번 대기하였다가 트랜잭션이 종료되면 그제야 조회가 가능할 테니 말이다.
반대로 case 2 처럼 row 별 락이 가능한 상황이라면 한 사용자가 동시성 문제를 낼 수 있는 동시에 여러 요청이 가능한 상태인지 확인하고 그 경우가 적거나 성능 저하가 감당 가능한 수준이라면 처리가 확실하고 예외 처리를 직접 하지 않아도 되는 비관적 락도 좋은 선택지가 될 것이다.
동시성 문제 해결 - 낙관적 락
읽기에 배타 락을 활용하여 아예 읽기를 수정 이후로 처리해 버려 동시성 문제를 풀었다. 다만 자원과 락을 사용하는 방식에 따라 데드락 문제가 발생할 수 있었고, 자원이 겹칠 경우 조회가 늦어질 수 있다는 단점이 있었다.
아예 동시성 문제를 생각하지 않고 쿼리 하면 어떨까? 동시성 문제를 생각하지 않고 트랜잭션을 처리했다가 혹 동시성 문제가 발생한다면 그때 동시성 문제를 애플리케이션에서 처리하는 것으로 데드락과 성능 문제를 풀어보는 것이다. 이를 낙관적 락이라고 한다.
동시성 문제가 발생했을 때 이를 확인하는 방법으로 row 별 버전을 사용한다. Entity 에 @Version 으로 Long, Integer, Timestamp 등의 타입으로 버전을 명시하면 이를 읽어 조회 때의 버전과 동일한지 확인하는 것으로 쉽게 구현한다.
트랜잭션 A와 B가 최신 버전을 조회하고 트랜잭션 A에서 update 로 버전을 업데이트하는 과정에서 트랜잭션 B의 업데이트는 lock 에 의해 대기하는데 트랜잭션 A가 커밋을 마쳐 반영되면 트랜잭션 B의 업데이트는 쿼리의 버전 정보와 DB row에 해당하는 버전이 일치하지 않아 문제를 확인하는 것이다.
@Entity
public class StorageUsage {
@Version
private Timestamp version;
}
추가로 "@Lock의 LockModeType.OPTIMISTIC" 을 이용하면 이런 버전 확인을 업데이트 쿼리만이 아니라 조회에서도 사용하게 되는데 Repeatable read 가 아닌 트랜잭션에서 여러 번 조회할 때 이 version 정보를 확인하는 것으로 한 트랜잭션 내 여러 번의 조회에서 동일한 값을 갖는지를 DB가 아닌 애플리케이션 수준에서 보장하게 된다.
앞선 조회에 락을 거는 비관적 락과 달리 낙관적 락은 조회에 락을 걸지 않아 단순 쿼리 성능상은 이점이 보인다. 그러나 version 정보가 맞지 않는 경우에는 이를 애플리케이션 내에서 직접 처리해줘야 하는 번거로움과 복잡함으로 결국 동시성 문제를 해결하기 위해선 비관적 락처럼 조회를 업데이트 이후로 대기시키거나, 데드락의 상황처럼 아예 포기하고 서버 응답을 내야 하는 것은 같을 것이다.
예를 들어 위 스토리지 저장 공간 확인 -> 업로드를 예시로 한다면 version 이 맞지 않아 예외가 발생한 상황에 대한 처리로 1. 재시도를 통해 다른 트랜잭션 종료를 기다리거나, 2. 아예 포기하고 서버 에러로 응답하는 식으로 처리할 수 있다. 낙관적 락으로 이 예외를 어떻게 처리할지, 동시성 문제가 발생했을 때 어떤 정책을 취할지에 대한 선택지를 얻을 수 있지만 동시성이 발생했을 때의 처리에 문제가 있거나 그 처리 비용이 너무 크면 오히려 배보다 배꼽이 큰 상황이 생길 수 도 있겠다.
동시성 문제 해결 - 분산 락
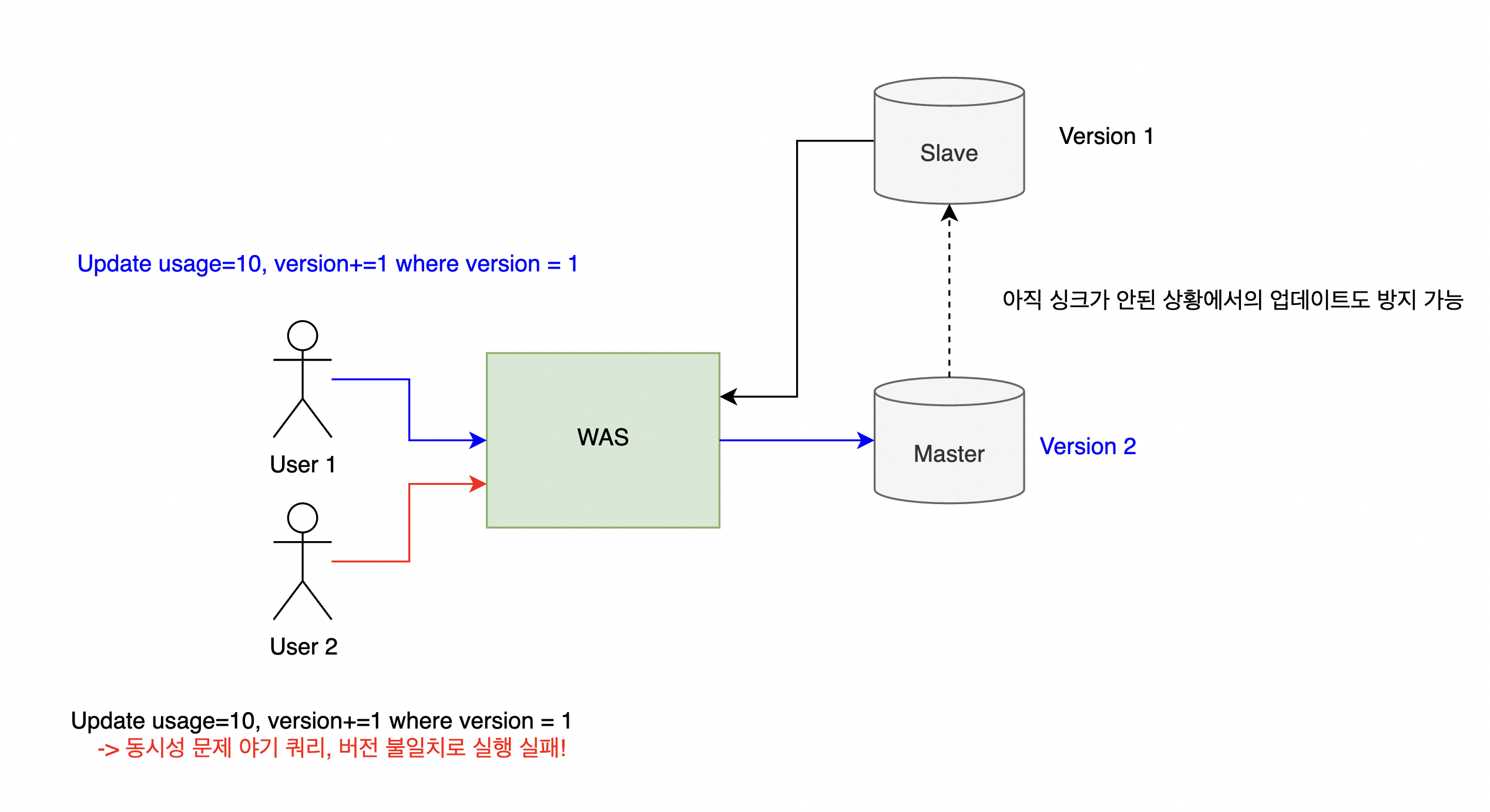
동시성이 발생할 수 있는 로직이 여러 DB 에 걸쳐있거나, 여러 트랜잭션을 사용한다면 DB 락으로 동시성 문제를 처리하기 어렵다. 예를 들어 레플리케이션이 적용되어 있고 한 로직 안에서도 읽기는 Slave 에서, 쓰기는 Master DB에서 읽어온다고 가정해 보자. 비관적 락으로 조회에 락을 사용해도 이는 Slave DB에, 업데이트에 사용되는 락은 Master DB에 걸리기 때문에 서로 다른 락으로 고립이 불가능하다.
이런 경우 비관적 락보다는 낙관적 락으로 락이 아닌 데이터의 버전 정보를 이용한 동시성 문제 해결이 좋은 방법이 될 수 있을 것 같다. 업데이트 쿼리에서 현재 저장 버전과 다른 버전으로의 업데이트를 막는 것으로 동시성 문제에서 벗어나고, Sync 가 아직 안된 DB 에서 이전 버전을 조회하고 잘못된 데이터로 업데이트를 시도하는 경우도 방지가 가능하다.
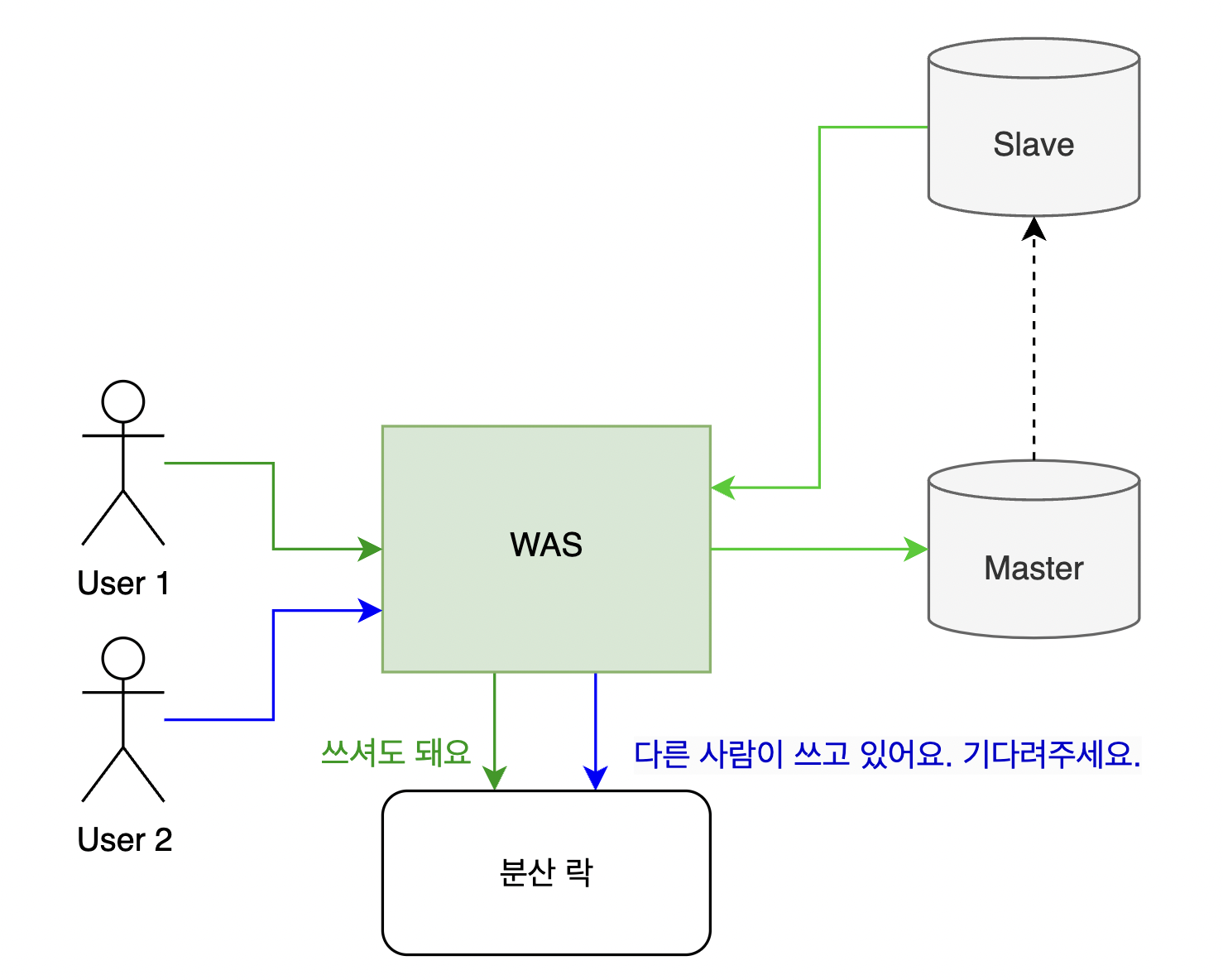
또는 위 상황과 더불어 DB 가 아닌 자원을 동시에 다루는 과정의 동시성 문제를 해결하고자 하는 경우 분산 락을 사용할 수 있다. 분산 락은 이런 DB 락을 사용하기 어렵거나 자원이 분리되어 있는 상황에서, 외부에 자원의 접근 가능 여부를 관리하는 또 다른 저장소를 두는 것으로 동시성 문제를 해결한다.
대표적인 분산락인 Mysql 의 Named lock은 DB에 자원의 접근 권한 가능 여부를 저장하고 해당 DB의 락으로 접근 권한 가능 여부 데이터의 동시성 문제를 해결하고, WAS에선 이 접근 권한을 얻어 요청을 순차적으로 처리할 수 있도록 하는 것으로 동시성 문제를 해결할 수 있다.
또 Redis 처럼 아예 저장소 자체를 싱글 스레드로 하고 WAS는 이 저장소에서 접근 권한을 얻는 것으로 공유 자원이 여러 흐름에 의해 동시에 처리되어 동시성 문제가 생기는 상황을 막는 방법도 있다. 특히 Redis 클라이언트 중 redisson 은 pub / sub 이 가능해서 자원을 대기하는 흐름들은 subscribe 를 요청하고, 자원 점유를 마친 흐름은 점유 마침 이벤트를 publish 하는 것으로 흐름들에게 자원을 획득할 수 있는 기회가 다시 생겼음을 알릴 수 있어 자원 획득 가능을 지속적으로 확인해야 하는 Spin Lock 방식에 비해 성능상 유리하여 분산락으로 사용되기 좋다.
다만, 운영체제를 공부할 때 자원의 처리가 빠르거나 컨텍스트 스위칭 비용이 큰 상황처럼 오히려 Spin lock 방식으로 흐름을 잃지 않고 단시간 자원 획득 가능 여부 확인을 지속하는 것이 유리한 경우도 있다고 배웠는데 이런 상황이 얼마나 많은지, Redisson 에도 적용되는 말인지는 확인해 보진 못 했다.
낙관적 락과 비관적 락 선택 방법??
많은 블로그에서 비관적 락과 낙관적 락을 비교할 때 출동시 낙관적 락이 성능 저하가 크고, 충돌이 없는 경우 낙관적 락의 성능이 좋다고 정리해 둔 곳이 많았다. 또 그렇기에 충돌이 빈번하지 않을 때는 낙관적 락을, 충돌이 빈번한 경우에는 비관적 락을 사용하라는 정보가 많았다.
음 내가 경험이 적어서인지, 아니면 쉽게 설명하기 위해 간단히 설명해둔건지 그 단순한 선택 기준이 사실 잘 납득이 되지 않았다. 상황이 너무 다양하고 고려해야 하는게 훨씬 더 많아서 단순히 충돌이 많냐 적냐로 락 방식을 결정하기 어렵지 않냐는게 지금 내 생각이다. 물론 틀릴 수도 있다.
예를 들어 만약 충돌이 빈번한데 DB 처리량이 많고, 처리 시간이 긴 상황이라면, DB 락으로 다른 트랜잭션이 처리되길 끝날 때까지 커넥션을 물고 있는 비관적 락보다는 차라리 낙관적 락으로 커넥션을 놓아주고 기다리는게 전체 애플리케이션 성능으로는 더 이점이 있지 않을까 생각해본다.
또 반대로 충돌이 빈번하지 않은 경우에서 낙관적 락을 구현하고 동시성 문제를 발생했을 때의 예외 처리, 재시도 처리를 직접 하면서 새로운 정책이나 코드 라인을 만들어 관리 포인트를 늘리는 것보다, 코드와 정책을 더 명확하게 하고 확실한 동시성 문제 해결을 위해 깔끔하게 비관적 락을 사용하는 것도 좋은 근거가 될 수 있겠다.
충돌이 빈번하면 비관적 락이 좋고, 빈번하지 않으면 낙관적 락이 좋다라는 기준이 통하는 상황이 있고, 또 그렇지 않은 상황도 많으니 진리라는 생각보다는 더 많은 고려 사항을 검토해봐도 좋을 것 같다.
'Architecture > Application' 카테고리의 다른 글
| 이벤트 발행과 DB 트랜잭션 원자성 유지, Transaction outbox pattern (0) | 2024.06.01 |
|---|---|
| 두 번의 갱신 분실 문제와 락 (12) | 2024.01.23 |
| Future 를 활용한 비동기 이미지 비동기 업로드 흐름과 시연 (0) | 2023.11.28 |
| 레디스 주요 옵션과 사용 전략 (4) | 2023.11.20 |
| 도메인 이벤트를 이용하여 의존성 분리 연습 (4) | 2022.01.12 |